
The Anti-Kyte

Freddie Starr Ate My File ! Finding out exactly what the Oracle Filewatcher is up to
As useful as they undoubtedly are, any use of a DBMS_SCHEDULER File Watchers in Oracle is likely to involve a number of moving parts.
This can make trying to track down issues feel a bit like being on a hamster wheel.
Fortunately, you can easily find out just exactly what the filewatcher is up to, if you know where to look …
I’ve got a procedure to populate a table with details of any arriving file.
create table incoming_files(
destination VARCHAR2(4000),
directory_path VARCHAR2(4000),
actual_file_name VARCHAR2(4000),
file_size NUMBER,
file_timestamp TIMESTAMP WITH TIME ZONE)
/
create or replace procedure save_incoming_file( i_result sys.scheduler_filewatcher_result)
as
begin
insert into incoming_files(
destination,
directory_path,
actual_file_name,
file_size,
file_timestamp)
values(
i_result.destination,
i_result.directory_path,
i_result.actual_file_name,
i_result.file_size,
i_result.file_timestamp);
end;
/
The filewatcher and associated objects that will invoke this procedure are :
begin
dbms_credential.create_credential
(
credential_name => 'starr',
username => 'fstarr',
password => 'some-complex-password'
);
end;
/
begin
dbms_scheduler.create_file_watcher(
file_watcher_name => 'freddie',
directory_path => '/u01/app/upload_files',
file_name => '*.txt',
credential_name => 'starr',
enabled => false,
comments => 'Feeling peckish');
end;
/
begin
dbms_scheduler.create_program(
program_name => 'snack_prog',
program_type => 'stored_procedure',
program_action => 'save_incoming_file',
number_of_arguments => 1,
enabled => false);
-- need to make sure this program can see the message sent by the filewatcher...
dbms_scheduler.define_metadata_argument(
program_name => 'snack_prog',
metadata_attribute => 'event_message',
argument_position => 1);
-- Create a job that links the filewatcher to the program...
dbms_scheduler.create_job(
job_name => 'snack_job',
program_name => 'snack_prog',
event_condition => null,
queue_spec => 'freddie',
auto_drop => false,
enabled => false);
end;
/
The relevant components have been enabled :
begin
dbms_scheduler.enable('freddie');
dbms_scheduler.enable('snack_prog');
dbms_scheduler.enable('snack_job');
end;
/
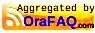
… and – connected on the os as fstarr – I’ve dropped a file into the directory…
echo 'Squeak!' >/u01/app/upload_files/hamster.txtFile watchers are initiated by a scheduled run of the SYS FILE_WATCHER job.
The logging_level value determines whether or not the executions of this job will be available in the *_SCHEDULER_JOB_RUN_DETAILS views.
select program_name, schedule_name,
job_class, logging_level
from dba_scheduler_jobs
where owner = 'SYS'
and job_name = 'FILE_WATCHER'
/
PROGRAM_NAME SCHEDULE_NAME JOB_CLASS LOGGING_LEVEL
-------------------- ------------------------- ----------------------------------- ---------------
FILE_WATCHER_PROGRAM FILE_WATCHER_SCHEDULE SCHED$_LOG_ON_ERRORS_CLASS FULL
If the logging_level is set to OFF (which appears to be the default in 19c), you can enable it by connecting as SYSDBA and running :
begin
dbms_scheduler.set_attribute('FILE_WATCHER', 'logging_level', dbms_scheduler.logging_full);
end;
/
The job is assigned the FILE_WATCHER_SCHEDULE, which runs every 10 minutes by default. To check the current settings :
select repeat_interval
from dba_scheduler_schedules
where schedule_name = 'FILE_WATCHER_SCHEDULE'
/
REPEAT_INTERVAL
------------------------------
FREQ=MINUTELY;INTERVAL=10
The thing is, there are times when the SYS.FILE_WATCHER seems to slope off for a tea-break. So, if you’re wondering why your file has not been processed yet, it’s handy to be able to check if this job has run when you expected it to.
In this case, as logging is enabled, we can do just that :
select log_id, log_date, instance_id, req_start_date, actual_start_date
from dba_scheduler_job_run_details
where owner = 'SYS'
and job_name = 'FILE_WATCHER'
and log_date >= sysdate - (1/24)
order by log_date desc
/
LOG_ID LOG_DATE INSTANCE_ID REQ_START_DATE ACTUAL_START_DATE
------- ----------------------------------- ----------- ------------------------------------------ ------------------------------------------
1282 13-APR-24 14.50.47.326358000 +01:00 1 13-APR-24 14.50.47.000000000 EUROPE/LONDON 13-APR-24 14.50.47.091753000 EUROPE/LONDON
1274 13-APR-24 14.40.47.512172000 +01:00 1 13-APR-24 14.40.47.000000000 EUROPE/LONDON 13-APR-24 14.40.47.075846000 EUROPE/LONDON
1260 13-APR-24 14.30.47.301176000 +01:00 1 13-APR-24 14.30.47.000000000 EUROPE/LONDON 13-APR-24 14.30.47.048977000 EUROPE/LONDON
1248 13-APR-24 14.20.47.941210000 +01:00 1 13-APR-24 14.20.47.000000000 EUROPE/LONDON 13-APR-24 14.20.47.127769000 EUROPE/LONDON
1212 13-APR-24 14.10.48.480193000 +01:00 1 13-APR-24 14.10.47.000000000 EUROPE/LONDON 13-APR-24 14.10.47.153032000 EUROPE/LONDON
1172 13-APR-24 14.00.50.676270000 +01:00 1 13-APR-24 14.00.47.000000000 EUROPE/LONDON 13-APR-24 14.00.47.111936000 EUROPE/LONDON
6 rows selected.
Even if the SYS.FILE_WATCHER is not logging, when it does run, any files being watched for are added to a queue, the contents of which can be found in SCHEDULER_FILEWATCHER_QT.
This query will get you the really useful details of what your filewatcher has been up to :
select
t.step_no,
treat( t.user_data as sys.scheduler_filewatcher_result).actual_file_name as filename,
treat( t.user_data as sys.scheduler_filewatcher_result).file_size as file_size,
treat( t.user_data as sys.scheduler_filewatcher_result).file_timestamp as file_ts,
t.enq_time,
x.name as filewatcher,
x.requested_file_name as search_pattern,
x.credential_name as credential_name
from sys.scheduler_filewatcher_qt t,
table(t.user_data.matching_requests) x
where enq_time > trunc(sysdate)
order by enq_time
/
STEP_NO FILENAME FILE_SIZE FILE_TS ENQ_TIME FILEWATCHER SEARCH_PATTERN CREDENTIAL_NAME
---------- --------------- ---------- -------------------------------- ---------------------------- --------------- --------------- ---------------
0 hamster.txt 8 13-APR-24 12.06.58.000000000 GMT 13-APR-24 12.21.31.746338000 FREDDIE *.txt STARR
Happily, in this case, our furry friend has avoided the Grim Squaker…
NOTE – No hamsters were harmed in the writing of this post.
If you think I’m geeky, you should meet my friend.
I’d like to talk about a very good friend of mine.
Whilst he’s much older than me ( 11 or 12 weeks at least), we do happen to share interests common to programmers of a certain vintage.
About a year ago, he became rather unwell.
Since then, whenever I’ve gone to visit, I’ve taken care to wear something that’s particular to our friendship and/or appropriately geeky.
At one point, when things were looking particularly dicey, I promised him, that whilst “Captain Scarlet” was already taken, if he came through he could pick any other colour he liked.
As a life-long Luton Town fan, his choice was somewhat inevitable.
So then, what follows – through the medium of Geeky T-shirts – is a portrait of my mate Simon The Indestructable Captain Orange…
When we first met, Windows 3.1 was still on everyone’s desktop and somewhat prone to hanging at inopportune moments. Therefore, we are fully aware of both the origins and continuing relevance of this particular pearl of wisdom :

Fortunately, none of the machines Simon was wired up to in the hospital seemed to be running any version of Windows so I thought he’d be reassured by this :

Whilst our first meeting did not take place on a World riding through space on the back of a Giant Turtle ( it was in fact, in Milton Keynes), Simon did earn my eternal gratitude by recommending the book Good Omens – which proved to be my gateway to Discworld.
The relevance of this next item of “Geek Chic” is that, when Simon later set up his own company, he decided that it should have a Latin motto.
In this, he was inspired by the crest of the Ankh-Morpork Assassins’ Guild :

His motto :
Nil codex sine Lucre
…which translates as …
No code without payment
From mottoes to something more akin to a mystic incantation, chanted whenever you’re faced with a seemingly intractable technical issue. Also, Simon likes this design so…

As we both know, there are 10 types of people – those who understand binary and those who don’t…

When confronted by something like this, I am able to recognise that the binary numbers are ASCII codes representing alphanumeric characters. However, I’ve got nothing on Simon, a one-time Assembler Programmer.
Whilst I’m mentally removing my shoes and socks in preparation to translate the message, desperately trying to remember the golden rule of binary maths ( don’t forget to carry the 1), he’ll just come straight out with the answer (“Geek”, in this case).
Saving the geekiest to last, I’m planning to dazzle with this on my next visit :

Techie nostalgia and a Star Wars reference all on the one t-shirt. I don’t think I can top that. Well, not for now anyway.
Using the APEX_DATA_EXPORT package directly from PL/SQL
As Data Warehouse developers, there is frequently a need for us to produce user reports in a variety of formats (ok, Excel).
Often these reports are the output of processes running as part of an unattended batch.
In the past I’ve written about some of the solutions out there for creating csv files and, of course Excel.
The good news is that, since APEX 20.2, Oracle provides the ability to do this out-of-the-box by means of the APEX_DATA_EXPORT PL/SQL package.
The catch is that you need to have an active APEX session to call it.
Which means you need to have an APEX application handy.
Fortunately, it is possible to initiate an APEX session and call this package without going anywhere near the APEX UI itself, as you’ll see shortly.
Specfically what we’ll cover is :
- generating comma-separated (CSV) output
- generating an XLSX file
- using the ADD_AGGREGATE procedure to add a summary
- using the ADD_HIGHLIGHT procedure to apply conditional formatting
- using the GET_PRINT_CONFIG function to apply document-wide styling
Additionally, we’ll explore how to create a suitable APEX Application from a script if one is not already available.
Incidentally, the scripts in this post can be found in this Github Repo.
Before I go any further, I should acknowledge the work of Amirreza Rastandeh, who’s LinkedIn article inspired this post.
A quick word on the Environment I used in these examples – it’s an Oracle supplied VirtualBox appliance running Oracle 23c Free Database and APEX 22.2.
Generating CSV outputAPEX_DATA_EXPORT offers a veritable cornucopia of output formats. However, to begin with, let’s keep things simple and just generate a CSV into a CLOB object so that we can check the contents directly from within a script.
We will need to call APEX_SESSION.CREATE_SESSION and pass it some details of an Apex application in order for this to work so the first thing we need to do is to see if we have such an application available :
select workspace, application_id, page_id, page_name
from apex_application_pages
order by page_id
/
WORKSPACE APPLICATION_ID PAGE_ID PAGE_NAME
------------------------------ -------------- ---------- --------------------
HR_REPORT_FILES 105 0 Global Page
HR_REPORT_FILES 105 1 Home
HR_REPORT_FILES 105 9999 Login Page
As long as we get at least one row back from this query, we’re good to go. Now for the script itself (called csv_direct.sql) :
set serverout on size unlimited
clear screen
declare
cursor c_apex_app is
select ws.workspace_id, ws.workspace, app.application_id, app.page_id
from apex_application_pages app
inner join apex_workspaces ws
on ws.workspace = app.workspace
order by page_id;
v_apex_app c_apex_app%rowtype;
v_stmnt varchar2(32000);
v_context apex_exec.t_context;
v_export apex_data_export.t_export;
begin
dbms_output.put_line('Getting app details...');
-- We only need the first record returned by this cursor
open c_apex_app;
fetch c_apex_app into v_apex_app;
close c_apex_app;
apex_util.set_workspace(v_apex_app.workspace);
dbms_output.put_line('Creating session');
apex_session.create_session
(
p_app_id => v_apex_app.application_id,
p_page_id => v_apex_app.page_id,
p_username => 'anynameyoulike' -- this parameter is mandatory but can be any string apparently
);
v_stmnt := 'select * from departments';
dbms_output.put_line('Opening context');
v_context := apex_exec.open_query_context
(
p_location => apex_exec.c_location_local_db,
p_sql_query => v_stmnt
);
dbms_output.put_line('Running Report');
v_export := apex_data_export.export
(
p_context => v_context,
p_format => 'CSV', -- patience ! We'll get to the Excel shortly.
p_as_clob => true -- by default the output is saved as a blob. This overrides to save as a clob
);
apex_exec.close( v_context);
dbms_output.put_line(v_export.content_clob);
end;
/
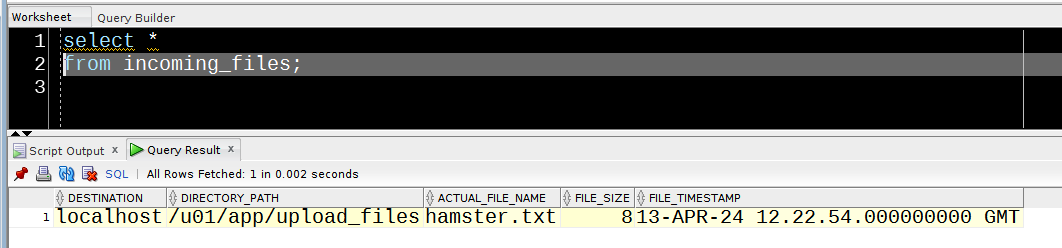
Running this we get :
Getting app details...
Creating session
Opening context
Running Report
DEPARTMENT_ID,DEPARTMENT_NAME,MANAGER_ID,LOCATION_ID
10,Administration,200,1700
20,Marketing,201,1800
30,Purchasing,114,1700
40,Human Resources,203,2400
50,Shipping,121,1500
60,IT,103,1400
70,Public Relations,204,2700
80,Sales,145,2500
90,Executive,100,1700
100,Finance,108,1700
110,Accounting,205,1700
120,Treasury,,1700
130,Corporate Tax,,1700
140,Control And Credit,,1700
150,Shareholder Services,,1700
160,Benefits,,1700
170,Manufacturing,,1700
180,Construction,,1700
190,Contracting,,1700
200,Operations,,1700
210,IT Support,,1700
220,NOC,,1700
230,IT Helpdesk,,1700
240,Government Sales,,1700
250,Retail Sales,,1700
260,Recruiting,,1700
270,Payroll,,1700
PL/SQL procedure successfully completed.
We can get away with using DBMS_OUTPUT as the result set is comparatively small. Under normal circumstances, you’ll probably want to save it into a table ( as in Amirreza’s post), or write it out to a file.
In fact, writing to a file is exactly what we’ll be doing with the Excel output we’ll generate shortly.
First though, what if you don’t have a suitable APEX application lying around…
Creating an APEX application from SQLNOTE – you only need to do this if you do not already have a suitable APEX Application available.
If you do then feel free to skip to the next bit, where we finally start generating XLSX files !
First, we need to check to see if there is an APEX workspace present for us to create the Application in :
select workspace, workspace_id
from apex_workspaces;
If this returns any rows then you should be OK to pick one of the workspaces listed and create your application in that.
Otherwise, you can create a Workspace by connecting to the database as a user with the APEX_ADMINISTRATOR_ROLE and running :
exec apex_instance_admin.add_workspace( p_workspace => 'HR_REPORT_FILES', p_primary_schema => 'HR');…where HR_REPORT_FILES is the name of the workspace you want to create and HR is a schema that has access to the database objects you want to run your reports against.
Next, following Jeffrey Kemp’s sage advice ,
I can just create and then export an Application on any compatible APEX instance and then simply import the resulting file.
That’s right, it’ll work irrespective of the environment on which the export file is created, as long as it’s a compatible APEX version.
If you need them, the instructions for exporting an APEX application are here.
I’ve just clicked through the Create Application Wizard to produce an empty application using the HR schema and have then exported it to a file called apex22_hr_report_files_app.sql.
To import it, I ran the following script:
begin
apex_application_install.set_workspace('HR_REPORT_FILES');
apex_application_install.generate_application_id;
apex_application_install.generate_offset;
end;
/
@/home/mike/Downloads/apex22_hr_report_files_app.sql
Once it’s run we can confirm that the import was successful :
select application_id, application_name,
page_id, page_name
from apex_application_pages
where workspace = 'HR_REPORT_FILES'
/
APPLICATION_ID APPLICATION_NAME PAGE_ID PAGE_NAME
-------------- -------------------- ---------- --------------------
105 Lazy Reports 0 Global Page
105 Lazy Reports 1 Home
105 Lazy Reports 9999 Login Page
The add_workspace.sql script in the Github Repo executes both the create workspace and application import steps described here.
Right, where were we…
Generating and Excel fileFirst we’ll need a directory object so we can write our Excel file out to disk. So, as a suitably privileged user :
create or replace directory hr_reports as '/opt/oracle/hr_reports';
grant read, write on directory hr_reports to hr;
OK – now to generate our report as an Excel…
set serverout on size unlimited
clear screen
declare
cursor c_apex_app is
select ws.workspace_id, ws.workspace, app.application_id, app.page_id
from apex_application_pages app
inner join apex_workspaces ws
on ws.workspace = app.workspace
order by page_id;
v_apex_app c_apex_app%rowtype;
v_stmnt varchar2(32000);
v_context apex_exec.t_context;
v_export apex_data_export.t_export;
-- File handling variables
v_dir all_directories.directory_name%type := 'HR_REPORTS';
v_fname varchar2(128) := 'hr_departments_reports.xlsx';
v_fh utl_file.file_type;
v_buffer raw(32767);
v_amount integer := 32767;
v_pos integer := 1;
v_length integer;
begin
open c_apex_app;
fetch c_apex_app into v_apex_app;
close c_apex_app;
apex_util.set_workspace(v_apex_app.workspace);
v_stmnt := 'select * from departments';
apex_session.create_session
(
p_app_id => v_apex_app.application_id,
p_page_id => v_apex_app.page_id,
p_username => 'whatever' -- any string will do !
);
-- Create the query context...
v_context := apex_exec.open_query_context
(
p_location => apex_exec.c_location_local_db,
p_sql_query => v_stmnt
);
-- ...and export the data into the v_export object
-- this time use the default - i.e. export to a BLOB, rather than a CLOB
v_export := apex_data_export.export
(
p_context => v_context,
p_format => apex_data_export.c_format_xlsx -- XLSX
);
apex_exec.close( v_context);
dbms_output.put_line('Writing file');
-- Now write the blob out to an xlsx file
v_length := dbms_lob.getlength( v_export.content_blob);
v_fh := utl_file.fopen( v_dir, v_fname, 'wb', 32767);
while v_pos <= v_length loop
dbms_lob.read( v_export.content_blob, v_amount, v_pos, v_buffer);
utl_file.put_raw(v_fh, v_buffer, true);
v_pos := v_pos + v_amount;
end loop;
utl_file.fclose( v_fh);
dbms_output.put_line('File written to HR_REPORTS');
exception when others then
dbms_output.put_line(sqlerrm);
if utl_file.is_open( v_fh) then
utl_file.fclose(v_fh);
end if;
end;
/
As you can see, this script is quite similar to the csv version. The main differences are that, firstly, we’re saving the output as a BLOB rather than a CLOB, simply by not overriding the default behaviour when calling APEX_DATA_EXPORT.EXPORT.
Secondly, we’re writing the result out to a file.
Once we retrieve the file and open it, we can see that indeed, it is in xlsx format :
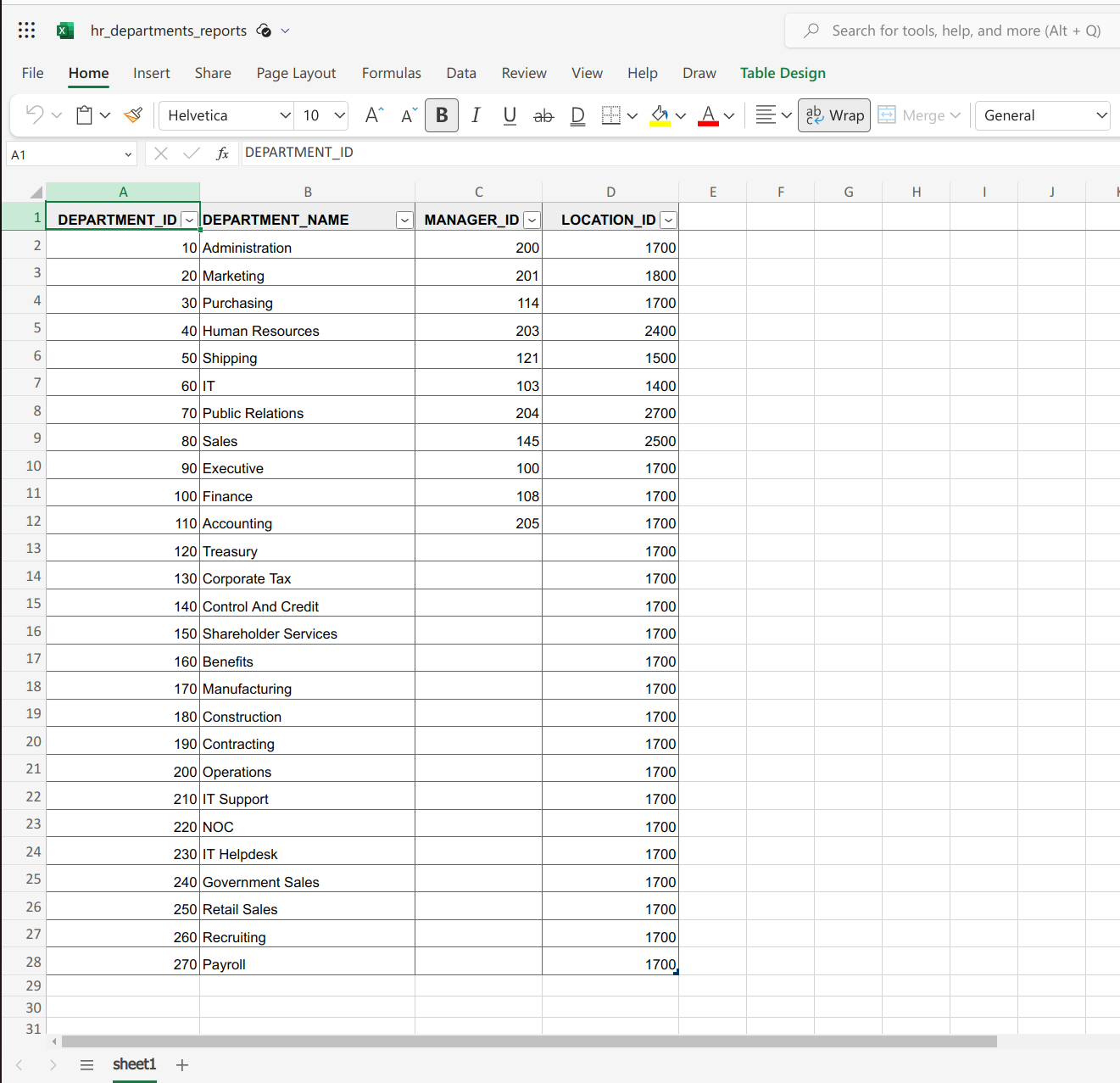
As well as generating a vanilla spreadsheet, APEX_DATA_EXPORT does have a few more tricks up it’s sleeve…
Adding an AggregationWe can add a row count to the bottom of our report by means of the ADD_AGGREGATE procedure.
To do so, we need to modify the report query to produce the data to be used by the aggregate :
select department_id, department_name, manager_id, location_id,
count( 1) over() as record_count
from departments';
As we don’t want to list the record count on every row, we need to exclude the record_count column from the result set by specifying the columns that we do actually want in the output. We can do this with calls to the ADD_COLUMN procedure :
apex_data_export.add_column( p_columns => v_columns, p_name => 'DEPARTMENT_ID');
apex_data_export.add_column( p_columns => v_columns, p_name => 'DEPARTMENT_NAME');
apex_data_export.add_column( p_columns => v_columns, p_name => 'MANAGER_ID');
apex_data_export.add_column( p_columns => v_columns, p_name => 'LOCATION_ID');
NOTE – column names passed in the P_NAME parameter in this procedure need to be in UPPERCASE.
Finally, we need to specify an aggregate itself using the ADD_AGGREGATE procedure :
apex_data_export.add_aggregate
(
p_aggregates => v_aggregates,
p_label => 'Data Row Count',
p_display_column => 'DEPARTMENT_ID',
p_value_column => 'RECORD_COUNT'
);
The finished script is called excel_aggregate.sql :
set serverout on size unlimited
clear screen
declare
cursor c_apex_app is
select ws.workspace_id, ws.workspace, app.application_id, app.page_id
from apex_application_pages app
inner join apex_workspaces ws
on ws.workspace = app.workspace
order by page_id;
v_apex_app c_apex_app%rowtype;
v_stmnt varchar2(32000);
v_columns apex_data_export.t_columns;
v_aggregates apex_data_export.t_aggregates;
v_context apex_exec.t_context;
v_export apex_data_export.t_export;
-- File handling variables
v_dir all_directories.directory_name%type := 'HR_REPORTS';
v_fname varchar2(128) := 'aggregate.xlsx';
v_fh utl_file.file_type;
v_buffer raw(32767);
v_amount integer := 32767;
v_pos integer := 1;
v_length integer;
begin
-- We only need the first record returned by this cursor
open c_apex_app;
fetch c_apex_app into v_apex_app;
close c_apex_app;
apex_util.set_workspace(v_apex_app.workspace);
apex_session.create_session
(
p_app_id => v_apex_app.application_id,
p_page_id => v_apex_app.page_id,
p_username => 'anynameyoulike'
);
-- Add a row with a count of the records in the file
-- We need to add the relevant data to the query and then format it
v_stmnt :=
'select department_id, department_name, manager_id, location_id,
count( 1) over() as record_count
from departments';
-- Make sure only the data columns to display on the report, not the record_count
-- NOTE - in all of these procs, column names need to be passed as upper case literals
apex_data_export.add_column( p_columns => v_columns, p_name => 'DEPARTMENT_ID');
apex_data_export.add_column( p_columns => v_columns, p_name => 'DEPARTMENT_NAME');
apex_data_export.add_column( p_columns => v_columns, p_name => 'MANAGER_ID');
apex_data_export.add_column( p_columns => v_columns, p_name => 'LOCATION_ID');
apex_data_export.add_aggregate
(
p_aggregates => v_aggregates,
p_label => 'Data Row Count',
p_display_column => 'DEPARTMENT_ID',
p_value_column => 'RECORD_COUNT'
);
v_context := apex_exec.open_query_context
(
p_location => apex_exec.c_location_local_db,
p_sql_query => v_stmnt
);
v_export := apex_data_export.export
(
p_context => v_context,
p_format => apex_data_export.c_format_xlsx, -- XLSX
p_columns => v_columns,
p_aggregates => v_aggregates
);
apex_exec.close( v_context);
v_length := dbms_lob.getlength( v_export.content_blob);
v_fh := utl_file.fopen( v_dir, v_fname, 'wb', 32767);
while v_pos <= v_length loop
dbms_lob.read( v_export.content_blob, v_amount, v_pos, v_buffer);
utl_file.put_raw(v_fh, v_buffer, true);
v_pos := v_pos + v_amount;
end loop;
utl_file.fclose( v_fh);
dbms_output.put_line('File written to HR_REPORTS');
exception when others then
dbms_output.put_line(sqlerrm);
if utl_file.is_open( v_fh) then
utl_file.fclose(v_fh);
end if;
end;
/
When we run this, we now get a row count row at the bottom of the file :
 Highlighting cells and rows
Highlighting cells and rows
The ADD_HIGHLIGHT procedure allows us to apply conditional formatting to individual cells, or even entire rows.
Once again the values to determine this behaviour need to be included in the report query.
In this case, we specify a highlight_id value to be used in rendering the row.
This time, I have a new query and I want to apply formatting based on the value of the SALARY column.
If the value is below 6000 then I want to make the text red ( by applying highlighter_id 1).
Otherwise, I want to set the background colour to green for the entire row ( highlighter_id 2).
The query therefore is this :
select first_name, last_name, salary,
case when salary < 6000 then 1 else 2 end as fair_pay
from employees
where job_id = 'IT_PROG'
Highlight 1 is :
-- text in red for id 1
apex_data_export.add_highlight(
p_highlights => v_highlights,
p_id => 1,
p_value_column => 'FAIR_PAY',
p_display_column => 'SALARY',
p_text_color => '#FF0000' );
…and highlight 2 is :
-- Whole row with green background for id 2
apex_data_export.add_highlight
(
p_highlights => v_highlights,
p_id => 2,
p_value_column => 'FAIR_PAY',
p_text_color => '#000000', -- black
p_background_color => '#00ffbf' -- green
);
The finished script is excel_highlight.sql :
set serverout on size unlimited
clear screen
declare
cursor c_apex_app is
select ws.workspace_id, ws.workspace, app.application_id, app.page_id
from apex_application_pages app
inner join apex_workspaces ws
on ws.workspace = app.workspace
order by page_id;
v_apex_app c_apex_app%rowtype;
v_stmnt varchar2(32000);
v_highlights apex_data_export.t_highlights;
v_context apex_exec.t_context;
v_export apex_data_export.t_export;
v_dir all_directories.directory_name%type := 'HR_REPORTS';
v_fname varchar2(128) := 'programmer_pay.xlsx';
v_fh utl_file.file_type;
v_buffer raw(32767);
v_amount integer := 32767;
v_pos integer := 1;
v_length integer;
begin
open c_apex_app;
fetch c_apex_app into v_apex_app;
close c_apex_app;
apex_util.set_workspace(v_apex_app.workspace);
apex_session.create_session
(
p_app_id => v_apex_app.application_id,
p_page_id => v_apex_app.page_id,
p_username => 'anynameyoulike'
);
-- Add a row with a count of the records in the file
-- We need to add the relevant data to the query and then format it
v_stmnt :=
q'[select first_name, last_name, salary,
case when salary < 6000 then 1 else 2 end as fair_pay
from employees
where job_id = 'IT_PROG']';
-- text in red for id 1
apex_data_export.add_highlight(
p_highlights => v_highlights,
p_id => 1,
p_value_column => 'FAIR_PAY',
p_display_column => 'SALARY',
p_text_color => '#FF0000' );
-- Whole row with green background for id 2
apex_data_export.add_highlight
(
p_highlights => v_highlights,
p_id => 2,
p_value_column => 'FAIR_PAY',
p_text_color => '#000000', -- black
p_background_color => '#00ffbf' -- green
);
v_context := apex_exec.open_query_context
(
p_location => apex_exec.c_location_local_db,
p_sql_query => v_stmnt
);
-- Pass the highlights object into the export
v_export := apex_data_export.export
(
p_context => v_context,
p_format => apex_data_export.c_format_xlsx,
p_highlights => v_highlights
);
apex_exec.close( v_context);
v_length := dbms_lob.getlength( v_export.content_blob);
v_fh := utl_file.fopen( v_dir, v_fname, 'wb', 32767);
while v_pos <= v_length loop
dbms_lob.read( v_export.content_blob, v_amount, v_pos, v_buffer);
utl_file.put_raw(v_fh, v_buffer, true);
v_pos := v_pos + v_amount;
end loop;
utl_file.fclose( v_fh);
dbms_output.put_line('File written to HR_REPORTS');
exception when others then
dbms_output.put_line(sqlerrm);
if utl_file.is_open( v_fh) then
utl_file.fclose(v_fh);
end if;
end;
/
…and the output…
 Formatting with GET_PRINT_CONFIG
Formatting with GET_PRINT_CONFIG
The GET_PRINT_CONFIG function offers a plethora of document formatting options…and a chance for me to demonstrate that I’m really more of a back-end dev.
To demonstrate just some of the available options, I have :
- changed the header and body font family to Times (default is Helvetica)
- set the heading text to be White and bold
- set the header background to be Dark Gray ( or Grey, if you prefer)
- set the body background to be Turquoise
- set the body font colour to be Midnight Blue
All of which looks like this :
v_print_config := apex_data_export.get_print_config
(
p_header_font_family => apex_data_export.c_font_family_times, -- Default is "Helvetica"
p_header_font_weight => apex_data_export.c_font_weight_bold, -- Default is "normal"
p_header_font_color => '#FFFFFF', -- White
p_header_bg_color => '#2F4F4F', -- DarkSlateGrey/DarkSlateGray
p_body_font_family => apex_data_export.c_font_family_times,
p_body_bg_color => '#40E0D0', -- Turquoise
p_body_font_color => '#191970' -- MidnightBlue
);
Note that, according to the documentation, GET_PRINT_CONFIG will also accept HTML colour names or RGB codes.
Anyway, the script is called excel_print_config.sql :
set serverout on size unlimited
clear screen
declare
cursor c_apex_app is
select ws.workspace_id, ws.workspace, app.application_id, app.page_id
from apex_application_pages app
inner join apex_workspaces ws
on ws.workspace = app.workspace
order by page_id;
v_apex_app c_apex_app%rowtype;
v_stmnt varchar2(32000);
v_context apex_exec.t_context;
v_print_config apex_data_export.t_print_config;
v_export apex_data_export.t_export;
-- File handling variables
v_dir all_directories.directory_name%type := 'HR_REPORTS';
v_fname varchar2(128) := 'crayons.xlsx';
v_fh utl_file.file_type;
v_buffer raw(32767);
v_amount integer := 32767;
v_pos integer := 1;
v_length integer;
begin
open c_apex_app;
fetch c_apex_app into v_apex_app;
close c_apex_app;
apex_util.set_workspace(v_apex_app.workspace);
apex_session.create_session
(
p_app_id => v_apex_app.application_id,
p_page_id => v_apex_app.page_id,
p_username => 'anynameyoulike'
);
v_stmnt := 'select * from departments';
v_context := apex_exec.open_query_context
(
p_location => apex_exec.c_location_local_db,
p_sql_query => v_stmnt
);
-- Let's do some formatting.
-- OK, let's just scribble with the coloured crayons...
v_print_config := apex_data_export.get_print_config
(
p_header_font_family => apex_data_export.c_font_family_times, -- Default is "Helvetica"
p_header_font_weight => apex_data_export.c_font_weight_bold, -- Default is "normal"
p_header_font_color => '#FFFFFF', -- White
p_header_bg_color => '#2F4F4F', -- DarkSlateGrey/DarkSlateGray
p_body_font_family => apex_data_export.c_font_family_times,
p_body_bg_color => '#40E0D0', -- Turquoise
p_body_font_color => '#191970' -- MidnightBlue
);
-- Specify the print_config in the export
v_export := apex_data_export.export
(
p_context => v_context,
p_format => apex_data_export.c_format_xlsx,
p_print_config => v_print_config
);
apex_exec.close( v_context);
v_length := dbms_lob.getlength( v_export.content_blob);
v_fh := utl_file.fopen( v_dir, v_fname, 'wb', 32767);
while v_pos <= v_length loop
dbms_lob.read( v_export.content_blob, v_amount, v_pos, v_buffer);
utl_file.put_raw(v_fh, v_buffer, true);
v_pos := v_pos + v_amount;
end loop;
utl_file.fclose( v_fh);
dbms_output.put_line('File written to HR_REPORTS');
exception when others then
dbms_output.put_line(sqlerrm);
if utl_file.is_open( v_fh) then
utl_file.fclose(v_fh);
end if;
end;
/
…and the resulting file is about as garish as you’d expect…

On the off-chance that you might prefer a more subtle colour scheme, you can find a list of HTML colour codes here.
Pi-Eyed and Clueless – Adventures with Board and Flash Drive
Since setting up my Raspberry Pi as a Plex Media Server a few years ago, the reliable application of Moore’s Law has brought us to a point where a humble USB flash drive now has sufficient capacity to cope with all of my media files and then some.
Therefore, I felt it was probably time to retire the powered external HDD that had been doing service as storage and replace it with a nice, compact stick.
 Existing Setup
Existing Setup
 …to new setup in 3 easy steps ( and several hard ones)
…to new setup in 3 easy steps ( and several hard ones)
The Pi in question is a Pi3 and is running Raspbian 11 (Bullseye).
The main consideration here was that I wanted to ensure that the new storage was visible to Plex from the same location as before so that I didn’t have to go through the rigmarole of validating and correcting all of the metadata that Plex retrieves for each media file ( Movie details etc).
Having copied the relevant files from the HDD to the new Flash Drive, I was ready to perform this “simple” admin task.
The steps to accomplish this are set out below.
Also detailed are some of the issues I ran into and how I managed to solve them, just in case you’ve stumbled across this post in a desparate search for a solution to your beloved fruit-based computer having turned into a slice of Brick Pi. In fact, let’s start with…
Pi not booting after editing /etc/fstabOn one occasion, after editing the fstab file and rebooting, I found the Pi unresponsive.
Having connected a display and keyboard to the Pi and starting it again, I was greeted with the message :
"You are in emergency mode. After logging in, type "journalctl -xb" to view system logs, "systemctl reboot to reboot, "systemctl default" or ^D to try again to boot into the default mode.
Press Enter to continue
…and after pressing enter…
"Cannot open access to console, the root accoutn is locked.
See sulogin(8) man page for more details.
Press Enter to continue...
…after which pressing Enter seems to have little effect.
According to this Stack Exchange thread, one solution would be to remove the SD card from the Pi, mount it on a suitable filesystem on alternative hardware ( e.g. a laptop) and edit the /etc/fstab file to remove the offending entry.
I took the other route…
Start by Rebooting and hold down the [Shift] key so that Raspbian takes you to the Noobs screen.
Now, from the top menu, select Edit config. This opens an editor with two tabs – config and cmdline.txt
We want to edit the cmdline.txt so click on that tab.
Despite appearances, this file is all on a single line so when you append to it, you need to add a space at the start and not a newline. To persuade Raspbian to give us access to a command prompt, we need to append :
init=/bin/shNow, save the file then choose Exit (Esc) from the NOOBS menu so that the Pi continues to boot.
You should now be resarded with a ‘#’ prompt.
At this point, the filesystem is mounted but is read only. As we want to fix the issue by editing (i.e. writing to) the /etc/fstab file, we need to remount it in read/write mode. We can do this by typing the following at the prompt :
mount -n -o remount,rw /Now, finally, I can use nano to remove the offending entry from /etc/fstab
nano /etc/fstabAt this point, you have the option of editing the cmdline.txt so that the Pi starts normally, by editing the file :
nano /boot/cmdline.txtAlternatively, you may prefer to let the Pi restart and hold down [SHIFT] and do the edit in the NOOBs screen.
You would then exit NOOBS and the Pi should boot normally.
Either way, we can reboot by typing :
reboot…at the prompt.
Hopefully, you won’t need to go through any of this pain as what follows did work as expected…
Unmounting the old driveFirst of all, we need to identify the device :
sudo fdisk -l |grep /dev/sdaIn my case, there’s just one device – /dev/sda1.
Now I need to unmount it :
umount /dev/sda1We then need to ensure that it isn’t mounted next time we boot
to do this, we need to edit /etc/fstab and comment out the appropriate entry :
sudo nano /etc/fstabRather than deleting it altogether, I’ve just commented it out the relevant line, in case I need to put it back for any reason :
# Below is entry for Seagate external HDD via a powered USB Hub
#UUID=68AE9F66AE9F2C16 /mnt/usbstorage ntfs nofail,uid=pi,gid=pi 0 0
In order to make sure that this has all worked as expected, I physically disconnect the external HDD from the pi and restart it with
sudo rebootWell, these days the simplest way to mount the drive is just to plug it in to one of the USB ports on the Pi. Raspbian then automagically mounts it to :
/media/pi
Initially, I thought I’d try to simply create a symbolic link under the now empty mount point where the external HDD used to live :
ln -s ../../media/pi/SanDisk/Media /mnt/usbstorage…and then restart the Plex Server…
sudo service plexmediaserver stop
sudo service plexmediaserver startUnfortunately, whilst we don’t get any errors on the command line, the Plex itself refuses to read the link and insisted that all of the media files under /mnt/usbstorage are “Unavailable”.
Therefore, we need to do things properly and explicitly mount the Flash Drive to the desired mount point.
First of all, we need to confirm the type of filesystem on the drive we want to mount.
Whilst fdisk gives us the device name, it seems to be hedging it’s bets as regards the filesystem type :
sudo fdisk -l |grep /dev/sda
Disk /dev/sda: 466.3 GiB, 500648902656 bytes, 977829888 sectors
/dev/sda1 7552 977829887 977822336 466.3G 7 HPFS/NTFS/exFAT
Fortunately, there’s a more reliable way to confirm the type, which gives as the UUID for the Flash Drive as well…
sudo blkid /dev/sda1
/dev/sda1: LABEL="SanDisk" UUID="8AF9-909A" TYPE="exfat" PARTUUID="c3072e18-01"
The type of the old external HDD was NTFS, so it’s likely I’ll need to download some packages to add exFat support on the pi :
sudo apt install exfat-fuse
sudo apt install exfat-utils
Once apt has done it’s thing and these packages are installed, we can then add an entry to fstab to mount the Flash Drive on the required directory every time the Pi starts :
sudo nano /etc/fstabThe line we need to add is in the format:
UUID=<flash drive UUID> <mount point> <file system type> <options> 0 0
The options I’ve chosen to specify are :
- defaults – use the default options rw, suid, dev, exec, auto, nouser and async
- users – Allow any user to mount and to unmount the filesystem, even when some other ordinary user mounted it.
- nofail – do not report errors for this device if it does not exist
- 0 – exclude from any system backup
- 0 – do not indluce this device in fsck check
So, my new entry is :
UUID=8AF9-909A /mnt/usbstorage exfat defaults,users,nofail 0 0
Once these changes are saved, we can check that the command will work :
unmount /dev/sda1
mount -a
If you don’t get any feedback from this command, it’s an indication that it worked as expected.
You should now be able to see the file system on the flash drive under /mnt/usbstorage :
ls -l /mnt/usbstorage/
total 2816
-rwxr-xr-x 1 root root 552605 Sep 23 2021 Install SanDisk Software.dmg
-rwxr-xr-x 1 root root 707152 Sep 23 2021 Install SanDisk Software.exe
drwxr-xr-x 5 root root 262144 Dec 31 16:19 Media
drwxr-xr-x 3 root root 262144 Apr 10 2018 other_plex_metadata
drwxr-xr-x 6 root root 262144 Mar 11 2017 Photos
-rwxr-xr-x 1 root root 300509 Sep 23 2021 SanDisk Software.pdf
One final step – reboot the pi once more to ensure that your mount is permanent.
With that done, I should be able to continue enjoying my media server, but with substantially less hardware.
ReferencesThere are a couple of sites that may be of interest :
There is an explanation of the fstab options here.
You can find further details on the cmdline.txt file here.
Using STANDARD_HASH to generate synthetic key values
In Oracle, identity columns are a perfect way of generating a synthetic key value as the underlying sequence will automatically provide you with a unique value every time it’s invoked, pretty much forever.
One minor disadvantage of sequence generated key values is that you cannot predict what they will be ahead of time.
This may be a bit of an issue if you need to provide traceability between an aggregated record and it’s component records, or if you want to update an existing aggregation in a table without recalculating it from scratch.
In such circumstances you may find yourself needing to write the key value back to the component records after generating the aggregation.
Even leaving aside the additional coding effort required, the write-back process may be quite time consuming.
This being the case, you may wish to consider an alternative to the sequence generated key value and instead, use a hashing algorithm to generate a unique key before creating the aggregation.
That’s your skeptical face.
You’re clearly going to take some convincing that this isn’t a completely bonkers idea.
Well, if you can bear with me, I’ll explain.
Specifically, what I’ll look at is :
- using the STANDARD_HASH function to generate a unique key
- the chances of the same hash being generated for different values
- before you rush out to buy a lottery ticket ( part one) – null values
- before you rush out to buy a lottery ticket (part two) – date formats
- before you rush out to buy a lottery ticket (part three) – synching the hash function inputs with the aggregation’s group by
- a comparison between the Hashing methods that can be used with STANDARD_HASH
Just before we dive in, I should mention Dani Schnider’s comprehensive article on this topic, which you can find here.
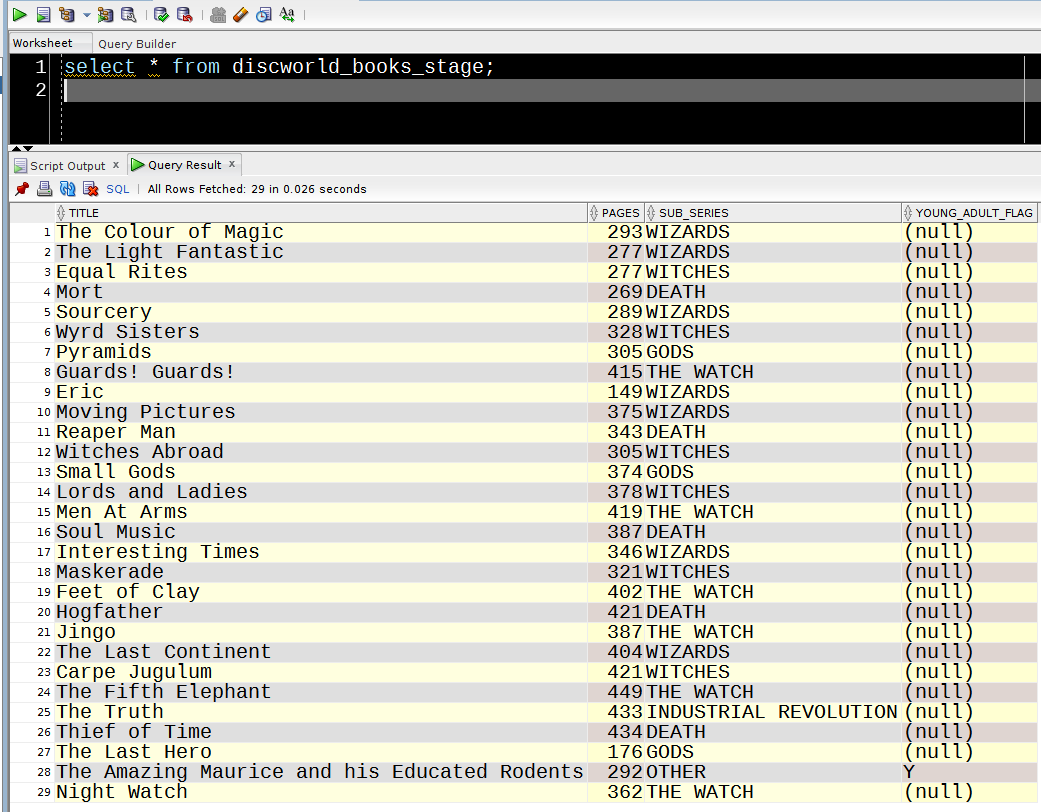
Example TableI have a table called DISCWORLD_BOOKS_STAGE – a staging table that currently contains :
select *
from discworld_books_stage;
TITLE PAGES SUB_SERIES YOUNG_ADULT_FLAG
---------------------- ---------- ---------------------- ----------------
The Wee Free Men 404 TIFFANY ACHING Y
Monstrous Regiment 464 OTHER
A Hat Full of Sky 298 TIFFANY ACHING Y
Going Postal 483 INDUSTRIAL REVOLUTION
Thud 464 THE WATCH
Wintersmith 388 TIFFANY ACHING Y
Making Money 468 INDUSTRIAL REVOLUTION
Unseen Academicals 533 WIZARDS
I Shall Wear Midnight 434 TIFFANY ACHING Y
Snuff 370 THE WATCH
Raising Steam 372 INDUSTRIAL REVOLUTION
The Shepherd's Crown 338 TIFFANY ACHING Y
I want to aggregate a count of the books and total number of pages by Sub-Series and whether the book is a Young Adult title and persist it in a new table, which I’ll be updating periodically as new data arrives.
Using the STANDARD_HASH function, I can generate a unique value for each distinct sub_series, young_adult_flag value combination by running :
select
standard_hash(sub_series||'#'||young_adult_flag||'#') as cid,
sub_series,
young_adult_flag,
sum(pages) as total_pages,
count(title) as number_of_books
from discworld_books_stage
group by sub_series, young_adult_flag
order by 1
/
CID SUB_SERIES YA TOTAL_PAGES NO_BOOKS
---------------------------------------- ------------------------- -- ----------- ----------
08B0E5ECC3FD0CDE6732A9DBDE6FF2081B25DBE2 WIZARDS 533 1
8C5A3FA1D2C0D9ED7623C9F8CD5F347734F7F39E INDUSTRIAL REVOLUTION 1323 3
A7EFADC5EB4F1C56CB6128988F4F25D93FF03C4D OTHER 464 1
C66E780A8783464E89D674733EC16EB30A85F5C2 THE WATCH 834 2
CE0E74B86FEED1D00ADCAFF0DB6DFB8BB2B3BFC6 TIFFANY ACHING Y 1862 5
OK, so we’ve managed to get unique values across a whole seven rows. But, lets face it, generating a synthetic key value in this way does introduce the risk of a duplicate hash being generated for multiple unique records.
As for how much of a risk…
Odds on a collisionIn hash terms, generating the same value for two different inputs is known as a collision.
The odds on this happening for each of the methods usable with STANDARD_HASH are :
MethodCollision OddsMD52^64SHA12^80SHA2562^128SHA3842^192SHA5122^256Figures taken from https://en.wikipedia.org/wiki/Hash_function_security_summaryBy default, STANDARD_HASH uses SHA1. The odds of a SHA1 collision are :
1 in 1,208,925,819,614,629,174,706,176
By comparison, winning the UK Lottery Main Draw is pretty much nailed on at odds of
1 in 45,057,474
So, if you do happen to come a cropper on that 12 octillion ( yes, that’s really a number)-to-one chance then your next move may well be to run out and by a lottery ticket.
Before you do, however, it’s worth checking to see that you haven’t fallen over one or more of the following…
Remember that the first argument we pass in to the STANDARD_HASH function is a concatenation of values.
If we have two nullable columns together we may get the same concatenated output where one of the values is null :
with nulltest as (
select 1 as id, 'Y' as flag1, null as flag2 from dual union all
select 2, null, 'Y' from dual
)
select id, flag1, flag2,
flag1||flag2 as input_string,
standard_hash(flag1||flag2) as hash_val
from nulltest
/
ID F F INPUT_STRING HASH_VAL
---------- - - ------------ ----------------------------------------
1 Y Y 23EB4D3F4155395A74E9D534F97FF4C1908F5AAC
2 Y Y 23EB4D3F4155395A74E9D534F97FF4C1908F5AAC
To resolve this, you can use the NVL function on each column in the concatenated input to the STANDARD_HASH function.
However, this is likely to involve a lot of typing if you have a large number of columns.
Instead, you may prefer to simply concatenate a single character after each column:
with nulltest as (
select 1 as id, 'Y' as flag1, null as flag2 from dual union all
select 2, null, 'Y' from dual
)
select id, flag1, flag2,
flag1||'#'||flag2||'#' as input_string,
standard_hash(flag1||'#'||flag2||'#') as hash_val
from nulltest
/
ID F F INPUT_STRING HASH_VAL
---------- - - ------------ ----------------------------------------
1 Y Y## 2AABF2E3177E9A5EFBD3F65FCFD8F61C3C355D67
2 Y #Y# F84852DE6DC29715832470A40B63AA4E35D332D1
Whilst concatenating a character into the input string does solve the null issue, it does mean we also need to consider…
Date FormatsIf you just pass a date into STANDARD_HASH, it doesn’t care about the date format :
select
sys_context('userenv', 'nls_date_format') as session_format,
standard_hash(trunc(sysdate))
from dual;
SESSION_FORMAT STANDARD_HASH(TRUNC(SYSDATE))
-------------- ----------------------------------------
DD-MON-YYYY 9A2EDB0D5A3D69D6D60D6A93E04535931743EC1A
alter session set nls_date_format = 'YYYY-MM-DD';
select
sys_context('userenv', 'nls_date_format') as session_format,
standard_hash(trunc(sysdate))
from dual;
SESSION_FORMAT STANDARD_HASH(TRUNC(SYSDATE))
-------------- ----------------------------------------
YYYY-MM-DD 9A2EDB0D5A3D69D6D60D6A93E04535931743EC1A
However, if the date is part of a concatenated value, the NLS_DATE_FORMAT will affect the output value as the date is implicitly converted to a string…
alter session set nls_date_format = 'DD-MON-YYYY';
Session altered.
select standard_hash(trunc(sysdate)||'XYZ') from dual;
STANDARD_HASH(TRUNC(SYSDATE)||'XYZ')
----------------------------------------
DF0A192333BDF860AAB338C66D9AADC98CC2BA67
alter session set nls_date_format = 'YYYY-MM-DD';
Session altered.
select standard_hash(trunc(sysdate)||'XYZ') from dual;
STANDARD_HASH(TRUNC(SYSDATE)||'XYZ')
----------------------------------------
FC2999F8249B89FE88D4C0394CC114A85DAFBBEF
Therefore, it’s probably a good idea to explicitly set the NLS_DATE_FORMAT in the session before generating the hash.
Use the same columns in the STANDARD_HASH as you do in the GROUP BYI have another table called DISCWORLD_BOOKS :
select sub_series, main_character
from discworld_books
where sub_series = 'DEATH';
SUB_SERIES MAIN_CHARACTER
-------------------- ------------------------------
DEATH MORT
DEATH DEATH
DEATH DEATH
DEATH SUSAN STO HELIT
DEATH LU TZE
If I group by SUB_SERIES and MAIN_CHARACTER, I need to ensure that I include those columns as input into the STANDARD_HASH function.
Otherwise, I’ll get the same hash value for different groups.
For example, running this will give us the same hash for each aggregated row in the result set :
select
sub_series,
main_character,
count(*),
standard_hash(sub_series||'#') as cid
from discworld_books
where sub_series = 'DEATH'
group by sub_series, main_character,
standard_hash(sub_series||main_character)
order by 1
/
SUB_SERIES MAIN_CHARACTER COUNT(*) CID
-------------------- ------------------------------ ---------- ----------------------------------------
DEATH MORT 1 5539A1C5554935057E60CBD021FBFCD76CB2EB93
DEATH DEATH 2 5539A1C5554935057E60CBD021FBFCD76CB2EB93
DEATH LU TZE 1 5539A1C5554935057E60CBD021FBFCD76CB2EB93
DEATH SUSAN STO HELIT 1 5539A1C5554935057E60CBD021FBFCD76CB2EB93
What we’re actually looking for is :
select
sub_series,
main_character,
count(*),
standard_hash(sub_series||'#'||main_character||'#') as cid
from discworld_books
where sub_series = 'DEATH'
group by sub_series, main_character,
standard_hash(sub_series||main_character)
order by 1
/
SUB_SERIES MAIN_CHARACTER COUNT(*) CID
-------------------- ---------------------- -------- ----------------------------------------
DEATH MORT 1 01EF7E9D4032CFCD901BB2A5A3E2A3CD6A09CC18
DEATH DEATH 2 167A14D874EA960F6DB7C2989A3E9DE07FAF5872
DEATH LU TZE 1 5B933A07FEB85D6F210825F9FC53F291FB1FF1AA
DEATH SUSAN STO HELIT 1 0DA3C5B55F4C346DFD3EBC9935CB43A35933B0C7
We’re going to populate this table :
create table discworld_subseries_aggregation
(
cid varchar2(128),
sub_series varchar2(50),
young_adult_flag varchar2(1),
number_of_books number,
total_pages number
)
/…with the current contents of the DISCWORLD_BOOKS_STAGE table from earlier. We’ll then cleardown the staging table, populate it with a new set of data and then merge it into this aggregation table.
alter session set nls_date_format = 'DD-MON-YYYY';
merge into discworld_subseries_aggregation agg
using
(
select
cast(standard_hash(sub_series||'#'||young_adult_flag||'#') as varchar2(128)) as cid,
sub_series,
young_adult_flag,
count(title) as number_of_books,
sum(pages) as total_pages
from discworld_books_stage
group by sub_series, young_adult_flag
) stg
on ( agg.cid = stg.cid)
when matched then update
set agg.number_of_books = agg.number_of_books + stg.number_of_books,
agg.total_pages = agg.total_pages + stg.total_pages
when not matched then insert ( cid, sub_series, young_adult_flag, number_of_books, total_pages)
values( stg.cid, stg.sub_series, stg.young_adult_flag, stg.number_of_books, stg.total_pages)
/
commit;
truncate table discworld_books_stage;
Once we’re run this, the conents of DISCWORLD_SUBSERIES_AGGREGATION is :

Next, we insert the rest of the Discworld books into the staging table :
And run the merge again :
alter session set nls_date_format = 'DD-MON-YYYY';
merge into discworld_subseries_aggregation agg
using
(
select
cast(standard_hash(sub_series||'#'||young_adult_flag||'#') as varchar2(128)) as cid,
sub_series,
young_adult_flag,
count(title) as number_of_books,
sum(pages) as total_pages
from discworld_books_stage
group by sub_series, young_adult_flag
) stg
on ( agg.cid = stg.cid)
when matched then update
set agg.number_of_books = agg.number_of_books + stg.number_of_books,
agg.total_pages = agg.total_pages + stg.total_pages
when not matched then insert ( cid, sub_series, young_adult_flag, number_of_books, total_pages)
values( stg.cid, stg.sub_series, stg.young_adult_flag, stg.number_of_books, stg.total_pages)
/
7 rows merged.
 Relative Performance of Hashing Methods
Relative Performance of Hashing Methods
Whilst you may consider the default SHA1 method perfectly adequate for generating unique values, it may be of interest to examine the relative performance of the other available hashing algorithms.
For what it’s worth, my tests on an OCI Free Tier 19c instance using the following script were not that conclusive :
with hashes as
(
select rownum as id, standard_hash( rownum, 'MD5' ) as hash_val
from dual
connect by rownum <= 1000000
)
select hash_val, count(*)
from hashes
group by hash_val
having count(*) > 1
/
Running this twice for each method,replacing ‘MD5’ with each of the available algorithms in turn :
MethodBest Runtime (secs)MD50.939SHA11.263SHA2562.223SHA3842.225SHA5122.280I would imagine that, among other things, performance may be affected by the length of the input expression to the function.
Dr Who and Oracle SQL Pivot
Dr Who recently celebrated it’s 60th Anniversary and the BBC marked the occasion by making all episodes since 1963 available to stream.
This has given me the opportunity to relive those happy childhood Saturday afternoons spent cowering behind the sofa watching Tom Baker
take on the most fiendish adversaries that the Costume department could conjure up in the days before CGI.
Like the Doctor, I too am I time traveller. OK, so I can only move forwards through time, but I do have some knowledge of the future.
For example, present me knows that future me is an idiot who will undoubtedly forget of the syntax for the Pivot command in Oracle SQL
next time he wants to pivot some VARCHAR2 columns.
So if you are future me, this is for you. You owe me a drink…
I have a simple table :
create table doctor_who
(
incarnation varchar2(50),
actor varchar2(100)
)
/
which I’ve populated with the following records :
select incarnation, actor
from doctor_who;
INCARNATION ACTOR
-------------------- ------------------------------
1st William Hartnell
2nd Patrick Troughton
3rd Jon Pertwee
4th Tom Baker
5th Peter Davison
6th Colin Baker
7th Sylvester McCoy
8th Paul McGann
9th Christopher Eccleston
10th David Tennant
11th Matt Smith
12th Peter Capaldi
13th Jodie Whittaker
14th David Tennant
15th Ncuti Gatwa
Fugitive Doctor Jo Martin
War Doctor John Hurt
17 rows selected.
If I want a query to return a single row which lists selected incarnations, I can do this :
select *
from
(
select
incarnation,
actor
from doctor_who
)
pivot
(
max(actor)
for incarnation in
(
'1st' as first,
'4th' as fourth,
'10th' as tenth,
'War Doctor' as war,
'Fugitive Doctor' as fugitive
)
)
/
Which returns :
FIRST FOURTH TENTH WAR FUGITIVE
------------- ----------- --------------- ------------- -------------------
William Hartnell Tom Baker David Tennant John Hurt Jo Martin
The first thing to notice here is that the PIVOT clause insists on an aggregate function for the column that holds the data you want to display.
Failure to use one results in :
ORA-56902: expect aggregate function inside pivot operation
Fortunately, the MAX function works happily with VARCHAR2 and doesn’t impact the data in ACTOR, because there’s only one value for each incarnation in our example.
Unsurprisingly, the subquery needs to include both the columns to pivot and those containing the values we want to display.
If you think having a list of Doctor Who Actors means that we already have quite enough stars, you can tweak the query so that we name the columns we’re querying in the SELECT clause.
Note that you can only use columns that you’ve defined in the PIVOT clause ( although you don’t have to use all of them) :
select fourth, tenth, war, fugitive
-- Not selecting "first", although it's defined in the PIVOT clause
-- may be useful when developing/debugging
from
(
select
incarnation,
actor
from doctor_who
)
pivot
(
max(actor)
for incarnation in
(
'4th' as fourth,
'10th' as tenth,
'War Doctor' as war,
'Fugitive Doctor' as fugitive,
'1st' as first
)
)
/
FOURTH TENTH WAR FUGITIVE
-------------------- -------------------- -------------------- --------------------
Tom Baker David Tennant John Hurt Jo Martin
Finally, as you’d expect, the PIVOT CLAUSE does not affect the number of rows read to process the query.
For that, we still need a good old fashoined WHERE CLAUSE in the subquery.
On my OCI 19c Free Tier instance, the plan for the above statement is :
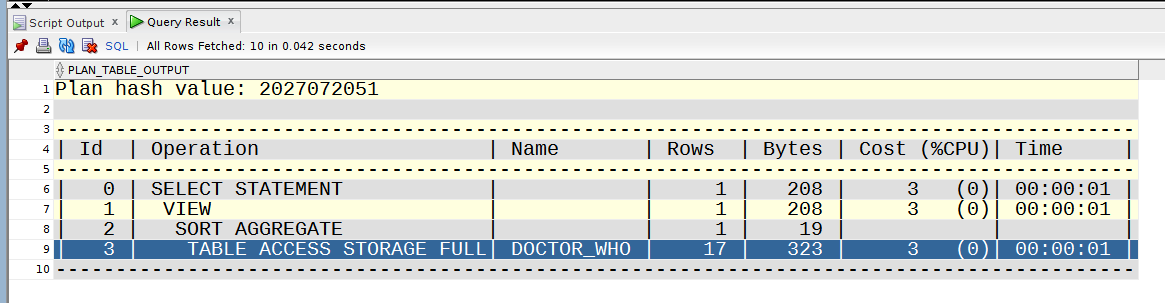
If we add a WHERE CLAUSE. however :
select fourth, tenth, war, fugitive
from
(
select
incarnation,
actor
from doctor_who
where incarnation in ('4th', '10th', 'War Doctor', 'Fugitive Doctor', '1st')
)
pivot
(
max(actor)
for incarnation in
(
'4th' as fourth,
'10th' as tenth,
'War Doctor' as war,
'Fugitive Doctor' as fugitive,
'1st' as first
)
)
/

Now that’s done, I can watch the next episode of Dr Who and the Sticky-back Plastic Monster. Unfortunately, I no longer fit behind the sofa.
Installing a Gnome Desktop Extension in Ubuntu
To distract myself from England’s ongoing woes at the Cricket World Cup, I’ve been playing the simple-yet-addictive London Tube Map Memory Game .
Having not taken the tube for a few years now, it’s proving something of a challenge.
It doesn’t help that they’ve added quite a few stations recently.
Another test of my memory occurs on those rare occasions where I want to terminate a frozen window on my Gnome desktop.
There’s an excellent utility called xkill which does the job…and which I can never remember the name of !
Fortunately there is a Gnome Shell Extension which will add an icon to the gnome-panel at the top of the screen so
it’s only a mouse-click away…
Let’s start with a quick look at xkill in action :
Before we go any further, it’s probably a good idea to confirm which versions of Ubuntu and Gnome I currently have running.
For Ubuntu itself :
cat /etc/release Ubuntu 22.04.3 LTS \n \l
…and for Gnome…
gnome-shell --version GNOME Shell 42.9Installing Extensions Manager
One way to manage Gnome Shell Extensions is to install the appropriately named Extension Manager.
To do this, open a Terminal and run :
sudo apt install gnome-shell-extension-manager
Once installed, you should then find Extension Manager in Activities :
Open it and you’ll see

Click the Browse tab to search for extensions
I know that the Extension I want is called Force Quit and the author is megh. Extension Manager can’t find the Extension by it’s name, but it does if we search for the author
Clicking the Install Button and confirming when prompted causes the extension to be installed and activiated.
We can now see it in the Activity Bar :
Let’s give it a try
Well, that’s one less thing to remember.
Back to ignoring the cricket !
Cut-and-Paste-Driven-Development – Using utPLSQL to build a test harness in Oracle.
If you’re working on a Decision Support System (DSS) then sooner or later you’re likely to need to create or change a package which runs as part of a lengthy batch process.
In such cirumstances, it would be useful to have a good old-fashioned test harness to run your code so you can test it’s functionality without having to kick off the entire batch.
Fortunately, utPLSQL is not just useful when it comes to TDD, CI/CD pipelines and the like. It can easily be used for the purpose of creating a simple stand-alone unit test for a single package.
Having used utPLSQL for this purpose quite regularly, I’ve found that my test harnesses tend to follow the same basic pattern.
What follows is a walkthrough of a typical utPLSQL package I might construct for this purpose.
Obviously, it won’t be to everyone’s taste but hopefully, you’ll find something of use in it.
If you’re interested, you can find the code in this Github Repo.
Testing ApproachThe main purpose of these tests is to check that the program being tested produces a set result for a set input.
Each individual test is structured in four sequential phases :
- Setup – setup the input data to use in the test
- Execute – run the test and retrieve the output
- Validate – check that the output matches what we expect
- Teardown – reset the everything back to how it was before we ran the test.
Whilst tables in DSS applications can contain a large number of columns, our test records only need to contain values that are :
- mandatory in the table ( or possibly part of an RI constraint or Unique Key)
- relevant to the test we’re conducting
In terms of the values themselves, they are not usually constrained other than by the definition of the column into which they are being inserted.
Therefore, we may be able to use negative numbers for integer identifiers to avoid clashes with any pre-existing records.
Also there may be nothing to stop us using random strings for VARCHAR2 values. Alternatively, if you’re easily amused, you may craft your test values to follow a theme. Not that I’d ever do anything so frivolous…
The database I’m running on is Oracle 19c on Oracle Cloud (Free Tier).
The version of utPLSQL used here is 3.1.13, downloaded from the Project’s Github Repo
It was installed without the DDL trigger by connecting to my OCI instance as the Admin user and following the appropriate instructions here.
The Code we’ll be TestingThe package we want to test performs updates on this table :
drop table employees_core;
create table employees_core
(
-- Columns populated by initial load
load_id number not null,
employee_id number not null,
first_name varchar2(20),
last_name varchar2(25),
email varchar2(25),
phone_number varchar2(20),
hire_date date,
job_id varchar2(10),
salary number,
commission_pct number,
manager_id number,
department_id number,
-- Additional columns populated as part of enrichment process
-- Job details
job_title varchar2(50),
-- Department Details
department_name varchar2(50),
-- Enrichment status
record_status varchar2(25),
constraint employees_core_pk primary key (load_id, employee_id)
)
/
To do so, it queries these tables :
create table departments
(
department_id number not null,
department_name varchar2(30) not null,
manager_id number,
location_id number,
constraint departments_pk primary key ( department_id)
)
/
create table jobs
(
JOB_ID varchar2(10) not null,
JOB_TITLE varchar2(35) not null,
MIN_SALARY number,
MAX_SALARY number,
constraint jobs_pk primary key( job_id)
)
/
The package itself is :
create or replace package enrich_employees
is
procedure department_details( i_load_id in number);
procedure job_details( i_load_id in number);
end;
/
create or replace package body enrich_employees
is
procedure department_details( i_load_id in number)
is
-- Populate the Department Name.
-- Suspend the record if we don't get a match.
begin
merge into employees_core emp
using departments dept
on
(
emp.department_id = dept.department_id
and emp.load_id = i_load_id
and emp.record_status = 'PROCESS'
)
when matched then update
set emp.department_name = dept.department_name;
update employees_core
set record_status = 'DEPARTMENT_ID_NOT_FOUND'
where record_status = 'PROCESS'
and department_name is null;
commit;
end department_details;
procedure job_details( i_load_id in number)
is
-- Don't suspend if we don't get a match, just leave the job_title empty.
begin
merge into employees_core emp
using jobs j
on
(
emp.job_id = j.job_id
and emp.record_status = 'PROCESS'
and emp.load_id = i_load_id
)
when matched then update
set emp.job_title = j.job_title;
commit;
end job_details;
end;
/
Note that, as is common in such routines, commits are done immediately after potentially large DML statements in order to minimise the length of time that Undo space is in use.
This is significant as we’ll need to account for it explicitly in our tests.
For the DEPARTMENT_DETAILS procedure, we want to check what happens when :
- we find a match in the DEPARTMENTS table
- we don’t find a match
- the DEPARTMENT_ID on the core record is null
For JOB_DETAILS, the conditions to test are similar :
- RECORD_STATUS is not ‘PROCESS’
- we find a match in the JOBS table
- we don’t find a match
- the JOB_ID is null
From this list of scenarios, we can construct our test package specification :
create or replace package enrich_employees_ut
as
--%suite(enrich_employees_ut)
--%rollback(Manual)
--%test( Department Lookup Succeeds)
procedure department_is_found;
--%test( Department does not exist)
procedure department_not_found;
--%test( Department ID is null)
procedure department_is_null;
--%test( Status is not PROCESS)
procedure status_not_process;
--%test( Job Lookup Succeeds)
procedure job_is_found;
--%test( Job does not exist)
procedure job_not_found;
--%test( Job ID is null)
procedure job_is_null;
end enrich_employees_ut;
The annotations we’re using here are :
--%suite(enrich_employees_ut)
…which allows us to the option to group multiple test packages into the same suite should we want to.
--%rollback(Manual)
…which prevents the Framework attempting it’s default rollback behaviour ( rollback to a savepoint) which won’t work here due to the commits in the code we’re testing.
--%test
…which identifies and describes the tests themselves.
Creating a Stub for the test Package BodyWe may well want to write tests and run them one-at-a-time so that we can adjust them ( or, indeed the code we’re testing) as we go.
In such circumstances, a script such as this, which uses the already created test package specification to generate a file containing the ddl for the package body, might come in handy :
clear screen
set heading off
set lines 130
set pages 500
set feedback off
set verify off
column pkg new_value v_package_name noprint
select '&1' as pkg from dual;
spool '&v_package_name..pkb'
with package_skeleton as
(
select 1 as line, 'create or replace package body &v_package_name' as text from dual
union
select line,
case
when line < ( select max(line) from user_source where name = upper('&v_package_name') and type = 'PACKAGE')
then
replace (
replace(
replace(text, '%test('),
')')
,';', q'[ is begin ut.fail('Not yet written'); end;]')
else text
end as text
from user_source
where name = upper('&v_package_name')
and type = 'PACKAGE'
and line > 1
and
(
regexp_replace(text, '[[:space:]]') not like '--\%%' escape '\'
or
regexp_replace(text, '[[:space:]]') like '--\%test%' escape '\'
)
)
select text from package_skeleton order by line
/
In this case, the generated package body looks like this, and compiles straight away :
create or replace package body enrich_employees_ut
as
-- Department Lookup Succeeds
procedure department_is_found is begin ut.fail('Not yet written'); end;
-- Department does not exist
procedure department_not_found is begin ut.fail('Not yet written'); end;
-- Department ID is null
procedure department_is_null is begin ut.fail('Not yet written'); end;
-- Status is not PROCESS
procedure status_not_process is begin ut.fail('Not yet written'); end;
-- Job Lookup Succeeds
procedure job_is_found is begin ut.fail('Not yet written'); end;
-- Job does not exist
procedure job_not_found is begin ut.fail('Not yet written'); end;
-- Job ID is null
procedure job_is_null is begin ut.fail('Not yet written'); end;
end enrich_employees_ut;
I prefer to create global variables to hold the test data.
This is because each test is likely to use a similar data set so, this way, the variables only need to be declared once.
As we’re dealing with table rows here, I’m just declaring a single record variable for each table.
This makes it very simple to add columns that we want to populate as they’re pre-declared as part of the record type.
For this test, my globals are :
g_emp employees_core%rowtype; g_job jobs%rowtype; g_dept departments%rowtype; g_result employees_core%rowtype;
Next, we need a procedure to initialise these globals :
procedure set_globals
is
begin
-- start by setting the globals to the values required for the first test, which
-- I usually make the test for the most commonly expected behaviour
--
-- Values for Employees Core record
--
-- Making numeric values negative means that they are less likely to clash
-- with an existing sequence generated value
g_emp.load_id := -1;
g_emp.employee_id := -8;
-- However wide the table, we only have to populate mandatory columns, and
-- any columns we want for the tests...
g_emp.department_id := -64;
g_emp.record_status := 'PROCESS';
-- Job Id is a Varchar - no constraints on it other than length...
g_emp.job_id := 'WIZZARD';
--
-- Values for the Department Lookup ( starting with ones that we expect to find)
--
-- Values set independently of the EMPLOYEES_CORE values as we'll want to see what happens
-- if they DON't match, as well as if they do.
g_dept.department_id := -64;
g_dept.department_name := 'Cruel and Unusual Geography';
--
-- Values for the Job lookup
--
g_job.job_id := 'WIZZARD';
g_job.job_title := 'Professor';
end set_globals;
Then there is a procedure to create the test records using the global variable values.
This separation between initialising the globals and creating the records is needed so that we can “tweak” the values we use for each test as appropriate :
procedure setup_data
is
-- Populate the tables with our test data
begin
insert into employees_core values g_emp;
insert into departments values g_dept;
insert into jobs values g_job;
commit;
end setup_data;
This is followed by a procedure to retrieve the actual results of the program execution :
procedure fetch_results
is
cursor c_result is
select *
from employees_core
where load_id = g_emp.load_id
and employee_id = g_emp.employee_id;
begin
open c_result;
fetch c_result into g_result;
close c_result;
end fetch_results;
Finally, as we need to tidy up after we’ve finished, there’s a teardown procedure to remove any test records we’ve set up :
procedure teardown_data
is
-- Tidy up by removing the test data using unique values where possible.
begin
delete from employees_core
where employee_id = g_emp.employee_id
and load_id = g_emp.load_id;
delete from departments
where department_id = g_dept.department_id;
delete from jobs
where job_id = g_job.job_id;
commit;
end teardown_data;
You might think we’ve done quite a bit of typing without writing any tests. The payoff for this up-front effort becomes apparent when you start on the first test, as you’re pretty much just calling everything you’ve already written and only need to add a couple of expectations, and an exception handler :
-- Department Lookup Succeeds
procedure department_is_found
is
begin
-- Setup
set_globals;
setup_data;
-- Execute
enrich_employees.department_details(g_emp.load_id);
-- Get the actual results
fetch_results;
-- Validate
ut.expect( g_result.department_name).to_(equal(g_dept.department_name));
ut.expect( g_result.record_status).to_(equal('PROCESS'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
The exception handler is there to ensure that the teardown runs even if we hit an unexpected error.
This is more likely than usual as you’re developing the test code and (potentially) the code your testing iteratively when running these tests.
We can execute our test standalone :
set serverout on
exec ut.run('enrich_employees_ut.department_is_found');
enrich_employees_ut
Department Lookup Succeeds [.005 sec]
Finished in .007019 seconds
1 tests, 0 failed, 0 errored, 0 disabled, 0 warning(s)
PL/SQL procedure successfully completed.
The code for our second test is almost identical, apart from the change in one variable value and the expected results :
-- Department does not exist
procedure department_not_found
is
begin
-- Setup
set_globals;
-- Almost exactly the same as the first test excep...
g_emp.department_id := -4096;
setup_data;
-- Execute
enrich_employees.department_details(g_emp.load_id);
fetch_results;
-- Validate
ut.expect( g_result.department_name).to_(be_null());
ut.expect( g_result.record_status).to_(equal('DEPARTMENT_ID_NOT_FOUND'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
The rest of the test follow a broadly similar pattern.
The finished test package body looks like this :
create or replace package body enrich_employees_ut
as
-- Global variables for use in tests
g_emp employees_core%rowtype;
g_job jobs%rowtype;
g_dept departments%rowtype;
g_result employees_core%rowtype;
procedure set_globals
is
begin
g_emp.load_id := -1;
g_emp.employee_id := -8;
g_emp.department_id := -64;
g_emp.record_status := 'PROCESS';
g_emp.job_id := 'WIZZARD';
g_dept.department_id := -64;
g_dept.department_name := 'Cruel and Unusual Geography';
g_job.job_id := 'WIZZARD';
g_job.job_title := 'Professor';
end set_globals;
procedure setup_data
is
begin
insert into employees_core values g_emp;
insert into departments values g_dept;
insert into jobs values g_job;
commit;
end setup_data;
procedure fetch_results
is
cursor c_result is
select *
from employees_core
where load_id = g_emp.load_id
and employee_id = g_emp.employee_id;
begin
open c_result;
fetch c_result into g_result;
close c_result;
end fetch_results;
procedure teardown_data
is
-- Tidy up by removing the test data using unique values where possible.
begin
delete from employees_core
where employee_id = g_emp.employee_id
and load_id = g_emp.load_id;
delete from departments
where department_id = g_dept.department_id;
delete from jobs
where job_id = g_job.job_id;
commit;
end teardown_data;
-- Department Lookup Succeeds
procedure department_is_found
is
begin
-- Setup
set_globals;
setup_data;
-- Execute
enrich_employees.department_details(g_emp.load_id);
fetch_results;
-- Validate
ut.expect( g_result.department_name).to_(equal(g_dept.department_name));
ut.expect( g_result.record_status).to_(equal('PROCESS'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
-- Department does not exist
procedure department_not_found
is
begin
-- Setup
set_globals;
-- Almost exactly the same as the first test excep...
g_emp.department_id := -4096;
setup_data;
-- Execute
enrich_employees.department_details(g_emp.load_id);
fetch_results;
-- Validate
ut.expect( g_result.department_name).to_(be_null());
ut.expect( g_result.record_status).to_(equal('DEPARTMENT_ID_NOT_FOUND'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
-- Department ID is null
procedure department_is_null
is
begin
-- Setup
set_globals;
-- Again, just a single change required :
g_emp.department_id := null;
setup_data;
-- Execute
enrich_employees.department_details(g_emp.load_id);
fetch_results;
-- Validate
ut.expect( g_result.department_name).to_(be_null());
ut.expect( g_result.record_status).to_(equal('DEPARTMENT_ID_NOT_FOUND'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
-- Status is not PROCESS
procedure status_not_process
is
begin
-- Setup
set_globals;
-- This time set the status to prevent processing
g_emp.record_status := 'SUSPENDED';
setup_data;
-- Execute
enrich_employees.department_details(g_emp.load_id);
fetch_results;
-- Validate
ut.expect( g_result.department_name).to_(be_null());
ut.expect( g_result.record_status).to_(equal('SUSPENDED'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
-- JOB Lookup Succeeds
procedure job_is_found
is
begin
-- Setup
-- We can use the default values here
set_globals;
setup_data;
-- Execute
enrich_employees.job_details(g_emp.load_id);
fetch_results;
-- Validate
ut.expect( g_result.job_title).to_(equal(g_job.job_title));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
-- Job does not exist
procedure job_not_found
is
begin
-- Setup
set_globals;
g_emp.job_id := -32768;
setup_data;
-- Execute
enrich_employees.job_details(g_emp.load_id);
-- Get the actual results
fetch_results;
-- Validate
ut.expect( g_result.job_title).to_(be_null());
ut.expect( g_result.record_status).to_(equal('PROCESS'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
-- Job ID is null
procedure job_is_null
is
begin
-- Setup
set_globals;
g_emp.job_id := null;
setup_data;
-- Execute
enrich_employees.job_details(g_emp.load_id);
fetch_results;
-- Validate
ut.expect( g_result.job_title).to_(be_null());
ut.expect( g_result.record_status).to_(equal('PROCESS'));
-- Teardown
teardown_data;
exception when others then
dbms_output.put_line(dbms_utility.format_error_stack);
ut.fail('Unexpected Error');
teardown_data;
end;
end enrich_employees_ut;
To run all of the tests in a suite, I usually use a script like this, which handles recompilation of either the test package or the code unit being tested without raising all those pesky ORA-4068 errors :
exec dbms_session.modify_package_state(dbms_session.reinitialize);
clear screen
set serveroutput on size unlimited
exec ut.run('enrich_employees_ut');
enrich_employees_ut
Department Lookup Succeeds [.004 sec]
Department does not exist [.003 sec]
Department ID is null [.003 sec]
Status is not PROCESS [.003 sec]
Job Lookup Succeeds [.003 sec]
Job does not exist [.003 sec]
Job ID is null [.003 sec]
Finished in .026568 seconds
7 tests, 0 failed, 0 errored, 0 disabled, 0 warning(s)
PL/SQL procedure successfully completed.
Of course I will probably still need to run a batch at some point if I want to perform a full System Test and (optionally) a load test. For now however, I can be confident that my code is at least functionally correct.
A Performance Comparison between Oracle’s REGEXP_SUBSTR and SUBSTR functions
Oracle SQL offers support for POSIX regular expressions by means of a suite of native functions.
 “Regular Expressions are a pathway to many abilities that some consider…unnatural.“
“Regular Expressions are a pathway to many abilities that some consider…unnatural.“
Whilst providing the ability for complex search conditions that regular expressions offer, REGEXP_SUBSTR has acquired a reputation for being a fair bit slower when compared to the standard SUBSTR function.
What I’m going to demonstrate here is :
- how SUBSTR seems generally to be faster than REGEXP_SUBSTR
- how the performance of REGEXP_SUBSTR can improve dramatically when used with INSTR
- REGEXP_SUBSTR performs better when it matches the start of a string
To start with though, well discover why you’ll never see a Sith Lord on Sesame Street ( hint : it’s the way they count in a Galaxy Far, Far Away)…
A Test TableWe have a two-column table that looks like this :
create table star_wars_numbers
(
id number generated always as identity,
episode varchar2(4000)
)
/
insert into star_wars_numbers( episode)
values('Four');
insert into star_wars_numbers( episode)
values('Four|Five');
insert into star_wars_numbers( episode)
values('Four|Five|Six');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One|Two');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One|Two|Three');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One|Two|Three|Seven');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One|Two|Three|Seven|Three-and-a-bit');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One|Two|Three|Seven|Three-and-a-bit|Three and a bit less of a bit');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One|Two|Three|Seven|Three-and-a-bit|Three and a bit less of a bit|Eight');
insert into star_wars_numbers( episode)
values('Four|Five|Six|One|Two|Three|Seven|Three-and-a-bit|Three and a bit less of a bit|Eight|Nine');
commit;
Whilst the contents of the EPISODES column may be the result of arcane Sith ritual, Moof-Milker activity in the design process cannot be ruled out.
Either way, the EPISODES column contains up to 11 values, with multiple columns being separated by a ‘|’.
Extracting each value in SQLUsing SUBSTR and INSTR to separate out the values in EPISODES is, as ever, quite a bit of typing…
select
id,
episode,
substr
(
episode,
1,
case
when instr(episode, '|') > 0 then instr(episode, '|') -1
else length(episode)
end
) as "A New Hope",
case when instr(episode, '|', 1, 1) > 0 then
substr
(
episode,
instr(episode, '|', 1, 1) + 1, -- start
case
when instr(episode, '|', 1, 2) > 0 then instr(episode, '|', 1,2) -1
else length(episode)
end
-
instr(episode, '|', 1, 1)
)
end as "The Empire Strikes Back",
case when instr(episode, '|', 1, 2) > 0 then
substr( episode, instr(episode, '|', 1, 2) + 1,
case when instr(episode, '|', 1,3) > 0 then instr(episode, '|',1,3) - 1 else length(episode) end
-
instr(episode, '|', 1, 2))
end as "Return of the Jedi",
case when instr(episode, '|', 1, 3) > 0 then
substr( episode, instr(episode, '|', 1, 3) + 1,
case when instr(episode, '|', 1,4) > 0 then instr(episode, '|',1,4) - 1 else length(episode) end
-
instr(episode, '|', 1, 3))
end as "Phantom Menace",
case when instr(episode, '|', 1, 4) > 0 then
substr( episode, instr(episode, '|', 1, 4) + 1,
case when instr(episode, '|', 1,5) > 0 then instr(episode, '|',1,5) - 1 else length(episode) end
-
instr(episode, '|', 1, 4))
end as "Attack of the Clones",
case when instr(episode, '|', 1, 5) > 0 then
substr( episode, instr(episode, '|', 1, 5) + 1,
case when instr(episode, '|', 1,6) > 0 then instr(episode, '|',1,6) - 1 else length(episode) end
-
instr(episode, '|', 1, 5))
end as "Revenge of the Sith",
case when instr(episode, '|', 1, 6) > 0 then
substr( episode, instr(episode, '|', 1, 6) + 1,
case when instr(episode, '|', 1,7) > 0 then instr(episode, '|',1,7) - 1 else length(episode) end
-
instr(episode, '|', 1, 6))
end as "The Force Awakens",
case when instr(episode, '|', 1, 7) > 0 then
substr( episode, instr(episode, '|', 1, 7) + 1,
case when instr(episode, '|', 1,8) > 0 then instr(episode, '|',1,8) - 1 else length(episode) end
-
instr(episode, '|', 1, 7))
end as "Rogue One",
case when instr(episode, '|', 1, 8) > 0 then
substr( episode, instr(episode, '|', 1, 8) + 1,
case when instr(episode, '|', 1,9) > 0 then instr(episode, '|',1,9) - 1 else length(episode) end
-
instr(episode, '|', 1, 8))
end as "Solo",
case when instr(episode, '|', 1, 9) > 0 then
substr( episode, instr(episode, '|', 1, 9) + 1,
case when instr(episode, '|', 1, 10) > 0 then instr(episode, '|',1, 10) - 1 else length(episode) end
-
instr(episode, '|', 1, 9))
end as "The Last Jedi",
case when instr(episode, '|', 1, 10) > 0 then
substr( episode, instr(episode, '|', 1, 10) + 1,
case when instr(episode, '|', 1, 11) > 0 then instr(episode, '|',1, 11) - 1 else length(episode) end
-
instr(episode, '|', 1, 10))
end as "The Rise of Skywalker"
from star_wars_numbers
/
…although these days ( version 12c and later), we can save ourselves a bit of effort by using an inline function…
with function extract_episode( i_string in varchar2, i_pos in pls_integer)
return varchar2
is
begin
if i_pos = 1 then
return substr(i_string, 1, case when instr(i_string, '|') > 0 then instr(i_string, '|') - 1 else length(i_string) end);
end if;
return
case when instr(i_string, '|', 1, i_pos -1 ) > 0 then
substr( i_string, instr(i_string, '|', 1, i_pos -1) + 1,
case when instr(i_string, '|', 1, i_pos) > 0 then instr(i_string, '|',1, i_pos) - 1 else length(i_string) end
-
instr( i_string, '|', 1, i_pos - 1))
end;
end;
select
id, episode,
extract_episode( episode, 1) as "A New Hope",
extract_episode( episode, 2) as "Empire Strikes Back",
extract_episode( episode, 3) as "Return of the Jedi",
extract_episode( episode, 4) as "The Phantom Menace",
extract_episode( episode, 5) as "Attack of the Clones",
extract_episode( episode, 6) as "Revenge of the Sith",
extract_episode( episode, 7) as "The Force Awakens",
extract_episode( episode, 8) as "Rogue One",
extract_episode( episode, 9) as "Solo",
extract_episode( episode, 10) as "The Last Jedi",
extract_episode( episode, 11) as "The Rise of Skywalker"
from star_wars_numbers
/
Whether you find the equivalent regexp query more elegant or just horrible is somewhat subjective :
select
regexp_substr(episode, '[^|]+') as "A New Hope",
regexp_substr(episode, '[^|]+',1, 2) as "The Empire Strikes Back",
regexp_substr(episode, '[^|]+',1, 3) as "Return of the Jedi",
regexp_substr(episode, '[^|]+',1, 4) as "The Phantom Menace",
regexp_substr(episode, '[^|]+',1, 5) as "Attack of the Clones",
regexp_substr(episode, '[^|]+',1, 6) as "Revenge of the Sith",
regexp_substr(episode, '[^|]+',1, 7) as "The Force Awakens",
regexp_substr(episode, '[^|]+',1, 8) as "Rogue One",
regexp_substr(episode, '[^|]+',1, 9) as "Solo",
regexp_substr(episode, '[^|]+',1, 10) as "The Last Jedi",
regexp_substr(episode, '[^|]+',1, 11) as "The Rise of Skywalker"
from star_wars_numbers
/
Irrespective of aesthetic considerations, I should explain the regexp in use here, if only so I can understand it when I read this a few months from now :
[^|] - match any character that isn't pipe ("|")
+ - match one or more times
Next, we need to find out how the regexp function stacks up when it comes to performance, and we’re not going to find that with a mere 11 rows of data…
Performance Test SetupLet’s make some use of all that space in the Galaxy Far, Far Away…
create table galaxy (
id number generated always as identity,
episode varchar2(4000))
/
begin
for i in 1..100000 loop
insert into galaxy(episode)
select episode from star_wars_numbers;
commit;
end loop;
end;
/
exec dbms_stats.gather_table_stats(user, 'galaxy');
All of the following tests were run on Oracle 19c Enterprise Edition running on Oracle Linux.
Everything was run in a SQL*Plus session from the command line on the database server.
The queries were run in SQL*Plus with the following settings :
set lines 130 clear screen set autotrace trace set timing on
Each query was executed at least twice consecutively to ensure that results were not skewed by the state of the buffer cache.
It’s also worth noting that, I found no low-level explanation for the performance discrepancies between the two functions when trawling through trace files. Therefore, I’ve concentrated on elapsed time as the main performance metric in these tests.
Test 1 – All Fields extracted in the Select ClauseLet’s start with the SUBSTR function ( referred to as “Standard” henceforth) :
select
id,
substr
(
episode, -- input string
1, -- start position
case
when instr(episode, '|') > 0 then instr(episode, '|') -1
else length(episode)
end -- number of characters to extract
) as "A New Hope",
case when instr(episode, '|', 1, 1) > 0 then
substr
(
episode,
instr(episode, '|', 1, 1) + 1, -- start
case
when instr(episode, '|', 1, 2) > 0 then instr(episode, '|', 1,2) -1
else length(episode)
end
-
instr(episode, '|', 1, 1)
)
end as "The Empire Strikes Back",
case when instr(episode, '|', 1, 2) > 0 then
substr( episode, instr(episode, '|', 1, 2) + 1,
case when instr(episode, '|', 1,3) > 0 then instr(episode, '|',1,3) - 1 else length(episode) end
-
instr(episode, '|', 1, 2))
end as "Return of the Jedi",
case when instr(episode, '|', 1, 3) > 0 then
substr( episode, instr(episode, '|', 1, 3) + 1,
case when instr(episode, '|', 1,4) > 0 then instr(episode, '|',1,4) - 1 else length(episode) end
-
instr(episode, '|', 1, 3))
end as "Phantom Menace",
case when instr(episode, '|', 1, 4) > 0 then
substr( episode, instr(episode, '|', 1, 4) + 1,
case when instr(episode, '|', 1,5) > 0 then instr(episode, '|',1,5) - 1 else length(episode) end
-
instr(episode, '|', 1, 4))
end as "Attack of the Clones",
case when instr(episode, '|', 1, 5) > 0 then
substr( episode, instr(episode, '|', 1, 5) + 1,
case when instr(episode, '|', 1,6) > 0 then instr(episode, '|',1,6) - 1 else length(episode) end
-
instr(episode, '|', 1, 5))
end as "Revenge of the Sith",
case when instr(episode, '|', 1, 6) > 0 then
substr( episode, instr(episode, '|', 1, 6) + 1,
case when instr(episode, '|', 1,7) > 0 then instr(episode, '|',1,7) - 1 else length(episode) end
-
instr(episode, '|', 1, 6))
end as "The Force Awakens",
case when instr(episode, '|', 1, 7) > 0 then
substr( episode, instr(episode, '|', 1, 7) + 1,
case when instr(episode, '|', 1,8) > 0 then instr(episode, '|',1,8) - 1 else length(episode) end
-
instr(episode, '|', 1, 7))
end as "Rogue One",
case when instr(episode, '|', 1, 8) > 0 then
substr( episode, instr(episode, '|', 1, 8) + 1,
case when instr(episode, '|', 1,9) > 0 then instr(episode, '|',1,9) - 1 else length(episode) end
-
instr(episode, '|', 1, 8))
end as "Solo",
case when instr(episode, '|', 1, 9) > 0 then
substr( episode, instr(episode, '|', 1, 9) + 1,
case when instr(episode, '|', 1, 10) > 0 then instr(episode, '|',1, 10) - 1 else length(episode) end
-
instr(episode, '|', 1, 9))
end as "The Last Jedi",
case when instr(episode, '|', 1, 10) > 0 then
substr( episode, instr(episode, '|', 1, 10) + 1,
case when instr(episode, '|', 1, 11) > 0 then instr(episode, '|',1, 11) - 1 else length(episode) end
-
instr(episode, '|', 1, 10))
end as "The Rise of Skywalker"
from galaxy
/
Runnnig this query, we get :
1100000 rows selected.
Elapsed: 00:00:20.32
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
35857676 bytes sent via SQL*Net to client
811886 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
Before we look at the REGEXP_SUBSTR equivalent, it’s probably worth considering the more streamlined in-line function version of this query :
with function extract_episode( i_string in varchar2, i_pos in pls_integer)
return varchar2
is
begin
return
case when instr(i_string, '|', 1, i_pos -1 ) > 0 then
substr( i_string, instr(i_string, '|', 1, i_pos -1) + 1,
case when instr(i_string, '|', 1, i_pos) > 0 then instr(i_string, '|',1, i_pos) - 1 else length(i_string) end
-
instr( i_string, '|', 1, i_pos - 1))
end;
end;
select
id,
substr
(
episode,
1,
case
when instr(episode, '|') > 0 then instr(episode, '|') -1
else length(episode)
end
) as "A New Hope",
extract_episode( episode, 2) as "Empire Strikes Back",
extract_episode( episode, 3) as "Return of the Jedi",
extract_episode( episode, 4) as "The Phantom Menace",
extract_episode( episode, 5) as "Attack of the Clones",
extract_episode( episode, 6) as "Revenge of the Sith",
extract_episode( episode, 7) as "The Force Awakens",
extract_episode( episode, 8) as "Rogue One",
extract_episode( episode, 9) as "Solo",
extract_episode( episode, 10) as "The Last Jedi",
extract_episode( episode, 11) as "The Rise of Skywalker"
from galaxy
/
Whilst it’s a bit more readable, it’s also a lot slower :
1100000 rows selected.
Elapsed: 00:00:41.76
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
35857676 bytes sent via SQL*Net to client
810042 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
REGEXP_SUBSTR however, takes slow to a new level…
select id,
regexp_substr(episode, '[^|]+') as "A New Hope",
regexp_substr(episode, '[^|]+',1, 2) as "The Empire Strikes Back",
regexp_substr(episode, '[^|]+',1, 3) as "Return of the Jedi",
regexp_substr(episode, '[^|]+',1, 4) as "The Phantom Menace",
regexp_substr(episode, '[^|]+',1, 5) as "Attack of the Clones",
regexp_substr(episode, '[^|]+',1, 6) as "Revenge of the Sith",
regexp_substr(episode, '[^|]+',1, 7) as "The Force Awakens",
regexp_substr(episode, '[^|]+',1, 8) as "Rogue One",
regexp_substr(episode, '[^|]+',1, 9) as "Solo",
regexp_substr(episode, '[^|]+',1, 10) as "The Last Jedi",
regexp_substr(episode, '[^|]+',1, 11) as "The Rise of Skywalker"
from galaxy
/
1100000 rows selected.
Elapsed: 00:01:27.25
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
35857680 bytes sent via SQL*Net to client
809519 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
Now see what happens when we give REGEXP_SUBSTR a little help from the humble INSTR (the “hybrid” query) :
select id,
regexp_substr(episode, '[^|]+') as "A New Hope",
decode( instr(episode, '|'), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,1) + 1)) as "The Empire Strikes Back",
decode( instr(episode, '|',1, 2), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,2) + 1)) as "Return of the Jedi",
decode( instr(episode, '|',1, 3), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,3) + 1)) as "The Phantom Menace",
decode( instr(episode, '|',1, 4), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,4) + 1)) as "Attack of the Clones",
decode( instr(episode, '|',1, 5), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,5) + 1)) as "Revenge of the Sith",
decode( instr(episode, '|',1, 6), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,6) + 1)) as "The Force Awakens",
decode( instr(episode, '|',1, 7), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,7) + 1)) as "Rogue One",
decode( instr(episode, '|',1, 8), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,8) + 1)) as "Solo",
decode( instr(episode, '|',1, 9), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,9) + 1)) as "The Last Jedi",
decode( instr(episode, '|',1, 10), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,10) + 1)) as "The Rise of Skywalker"
from galaxy
/
Yes, I have cheated a bit on the aesthetics here by using the more compact DECODE instead of CASE.
However, this does not affect the runtime of the query, which is a bit faster than the pure REGEXP_SUBSTR equivalent :
1100000 rows selected.
Elapsed: 00:00:30.83
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
35857680 bytes sent via SQL*Net to client
810158 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
Test 1 Results Summary
Query MethodTime (secs)SUBSTR ( Standard)20.32REGEXP_SUBSTR with INSTR (Hybrid)30.83SUBSTR with in-line function41.76REGEXP_SUBSTR ( Regexp)87.25
The performance of the Hybrid approach does raise the question of how the REGEXP_SUBSTR compares when we’re just looking to extract a single field from a string, rather than all of them…
Test 2 – Extract the first field onlyIn this instance we’re just looking for the first field in EPISODES.
In this context, the hybrid approach doesn’t apply because we’re always starting our search at the start of the input string.
Starting, once again with the Standard approach :
select id,
substr
(
episode, 1,
case
when instr(episode, '|', 1,1) > 0 then instr(episode, '|', 1,1) -1
else length(episode)
end
) as "A New Hope"
from galaxy
/
1100000 rows selected.
Elapsed: 00:00:05.33
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
25086067 bytes sent via SQL*Net to client
808790 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
Now for REGEXP_SUBSTR :
select id,
regexp_substr( episode, '[^|]+') as "A New Hope"
from galaxy
/
1100000 rows selected.
Elapsed: 00:00:06.38
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
25086067 bytes sent via SQL*Net to client
808868 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
Interestingly, whilst it’s still not as fast, the Regexp runtime is only 20% longer than the Standard.
This contrasts markedly with the 430% longer that the Regexp took for our first test.
Test 2 Results Summary Query MethodTime (secs)Standard5.33Regexp6.38Does this relative performance hold true for any single field in the input string ?
Test 3 – Extract the last field onlyStarting with the Standard query :
select
id,
case when instr(episode, '|', 1, 10) > 0 then
substr( episode, instr(episode, '|', 1, 10) + 1,
case when instr(episode, '|', 1, 11) > 0 then instr(episode, '|',1, 11) - 1 else length(episode) end
-
instr(episode, '|', 1, 10))
end as "The Rise of Skywalker"
from galaxy
/
1100000 rows selected.
Elapsed: 00:00:05.44
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
25686033 bytes sent via SQL*Net to client
808915 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
Once again, the Regexp Query is much slower…
select
id,
regexp_substr(episode, '[^|]+',1, 11) as "The Rise of Skywalker"
from galaxy
/
1100000 rows selected.
Elapsed: 00:00:16.16
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
25686033 bytes sent via SQL*Net to client
808888 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
…unless we use the hybrid approach…
select
id,
decode( instr(episode, '|',1, 10), 0, null, regexp_substr(episode, '[^|]+', instr(episode, '|',1,10) + 1)) as "The Rise of Skywalker"
from galaxy
/
1100000 rows selected.
Elapsed: 00:00:05.60
Execution Plan
----------------------------------------------------------
Plan hash value: 3574103611
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1100K| 47M| 2089 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| GALAXY | 1100K| 47M| 2089 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
80459 consistent gets
7616 physical reads
0 redo size
25686033 bytes sent via SQL*Net to client
808736 bytes received via SQL*Net from client
73335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1100000 rows processed
Test 3 Results Summary
Query MethodTime (secs)Standard 5.44Hybrid 5.60Regexp16.16
Conclusions
These tests seem to bear out the fact that, in general, SUBSTR offers better performance than REGEXP_SUBSTR.
However, the performance of REGEXP_SUBSTR can be greatly improved if used in conjunction with INSTR.
As always, the decision as to which function to use will depend on the specific circumstances you find yourself in.
Things that make you go VAAARRRGGGHHHH ! – ORA-38104 in a Stored Program Unit
I do have some empathy with Lauren James getting quite cross at work.
OK, it’s not as pressurised as striving to reach a World Cup Quarter Final, but I am known to become somewhat annoyed when Oracle presents me with :
ORA-38104: Columns referenced in the ON Clause cannot be updated
The error itself is reasonable enough. The thing is though, that the offending merge statement will not trigger a compile-time error if it’s in a Stored Program Unit. Oh no.
Instead, Oracle will let you carry on in blissful ignorance and only give you the bad news at runtime…
Let’s say we have a table called TEAM_AVAILABILITY :
create table team_availability
(
squad_number number,
first_name varchar2(250),
last_name varchar2(250),
available_flag varchar2(1)
)
/
insert into team_availability( squad_number, first_name, last_name)
values( 1, 'Mary', 'Earps');
insert into team_availability( squad_number, first_name, last_name)
values( 2, 'Lucy', 'Bronze');
insert into team_availability( squad_number, first_name, last_name)
values( 3, 'Niamh', 'Charles');
insert into team_availability( squad_number, first_name, last_name)
values( 4, 'Keira', 'Walsh');
insert into team_availability( squad_number, first_name, last_name)
values( 5, 'Alex', 'Greenwood');
insert into team_availability( squad_number, first_name, last_name)
values( 6, 'Millie', 'Bright');
insert into team_availability( squad_number, first_name, last_name)
values( 7, 'Lauren', 'James');
insert into team_availability( squad_number, first_name, last_name)
values( 8, 'Georgia', 'Stanway');
insert into team_availability( squad_number, first_name, last_name)
values( 9, 'Rachel', 'Daly');
insert into team_availability( squad_number, first_name, last_name)
values( 10, 'Ella', 'Toone');
insert into team_availability( squad_number, first_name, last_name)
values( 11, 'Lauren', 'Hemp');
insert into team_availability( squad_number, first_name, last_name)
values( 12, 'Jordan', 'Nobbs');
insert into team_availability( squad_number, first_name, last_name)
values( 13, 'Hannah', 'Hampton');
insert into team_availability( squad_number, first_name, last_name)
values( 14, 'Lotte', 'Wubben-Moy');
insert into team_availability( squad_number, first_name, last_name)
values( 15, 'Esme', 'Morgan');
insert into team_availability( squad_number, first_name, last_name)
values( 16, 'Jess', 'Carter');
insert into team_availability( squad_number, first_name, last_name)
values( 17, 'Laura', 'Coombs');
insert into team_availability( squad_number, first_name, last_name)
values( 18, 'Chloe', 'Kelly');
insert into team_availability( squad_number, first_name, last_name)
values( 19, 'Bethany', 'England');
insert into team_availability( squad_number, first_name, last_name)
values( 20, 'Katie', 'Zelem');
insert into team_availability( squad_number, first_name, last_name)
values( 21, 'Ellie', 'Roebuck');
insert into team_availability( squad_number, first_name, last_name)
values( 22, 'Katie', 'Robinson');
insert into team_availability( squad_number, first_name, last_name)
values( 23, 'Alessia', 'Russo');
commit;
We have a procedure that we can use to mark a player as being unavailable for selection :
create or replace procedure mark_player_unavailable( i_squad_number team_availability.squad_number%type)
is
begin
merge into team_availability
using dual
on
(
squad_number = i_squad_number
and available_flag is null
)
when matched then update
set available_flag = 'N';
end mark_player_unavailable;
/
When we create the procedure, everything seems fine…
Procedure MARK_PLAYER_UNAVAILABLE compiled
However, running it causes Oracle to do the equivalent of a VAR check, which results in :
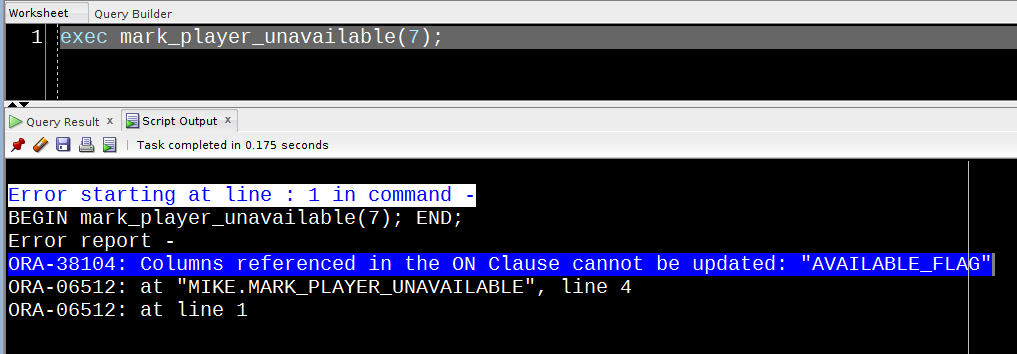
As to why Oracle does this, other than to annoy me, I have no idea.
Then again, I’m not sure why I keep falling into this trap either.
To avoid this altogether, there are a couple of options…
WorkaroundsWe could simply use an update instead of a merge
create or replace procedure mark_player_unavailable( i_squad_number team_availability.squad_number%type)
is
begin
update team_availability
set available_flag = 'N'
where squad_number = i_squad_number
and available_flag is null;
end mark_player_unavailable;
/
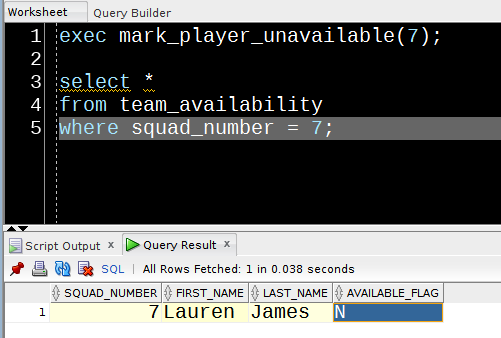
However, if we still want to use a merge, then we need to use an inline view in the USING clause :
create or replace procedure mark_player_unavailable( i_squad_number team_availability.squad_number%type)
is
begin
merge into team_availability ta
using
(
select tau.squad_number
from team_availability tau
where tau.squad_number = i_squad_number
and tau.available_flag is null
) ilv
on
(
ta.squad_number = ilv.squad_number
)
when matched then update
set ta.available_flag = 'N';
end mark_player_unavailable;
/
…which has the same result.
With my equanimity restored I can now reflect that yes, Womens football is different from the Mens. In the Womens game, England DO win penalty shoot-outs !
Happy Hatters and Oracle Interval Partitioning
I wouldn’t say that Simon is obsessed about Luton Town FC, but he has been known to express his affection through the medium of creosote :

Needless to say, he’s quite looking forward to next season as the Hatters have completed their Lazarus-like resurrection from the depths of the Conference to the pinnacle of English football – the Premier League.
Over the years, I’ve occasionally accompanied Simon to Kennelworth Road to watch Luton battle their way through the divisions, so it’s only fitting that I should pay tribute to their achievement in the examples that follow.
The technical subject at hand here is the advantages available when using Interval Partitioning syntax to Range Partition a table by a date.
As we’re talking about partitioning, he’s the standard warning about licensing…
Partitioning is usually an additional cost option on the Enterprise Edition license. It’s a really good idea to make sure that whatever platform you’re on is appropriately licensed before you use this feature.
For this post, I’ll be using 23c Free, which does include Partitioning.
We’ll start by creating a conventional Range Partitioned table and see what happens when we try to create data in a non-existent partition.
We’ll then try the same thing, but this time using an Interval Partitioned Table.
Finally, we’ll take a look at the SQL functions available to define intervals when creating Interval Partitions.
Partitioning by Date using conventional Range PartitioningFor the purposes of this example, I’m going to create a table which holds details of Luton’s final record for a League Season. I’m going to arbitrarily “end” each season on 30th June each year.
I’m going to separate each year into it’s own partition.
Whilst this may not be a realistic use of partitioning – you’re unlikely to create a table to hold a single row per partition – it does simplify the examples that follow :
create table luton_seasons
(
season_end_date date,
competition varchar2(25),
games_played number,
games_won number,
games_drawn number,
games_lost number,
goals_for number,
goals_against number,
points number,
finishing_position number,
notes varchar2(4000)
)
partition by range( season_end_date)
(
partition season_2013_14 values less than (to_date ('01-JUL-2014', 'DD-MON-YYYY')),
partition season_2014_15 values less than (to_date ('01-JUL-2015', 'DD-MON-YYYY')),
partition season_2015_16 values less than (to_date ('01-JUL-2016', 'DD-MON-YYYY')),
partition season_2016_17 values less than (to_date ('01-JUL-2017', 'DD-MON-YYYY')),
partition season_2017_18 values less than (to_date ('01-JUL-2018', 'DD-MON-YYYY'))
)
/
Populating the table works as you’d expect…
-- 2013-14
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2014', 'DD-MON-YYYY'),
'Conference',
46, 30, 11, 5, 102, 35, 101,
1, 'Promoted back to the Football League !'
);
-- 2014-15
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2015', 'DD-MON-YYYY'),
'League 2',
46, 19, 11, 16, 54, 44, 68,
8, null
);
-- 2015-16
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2016', 'DD-MON-YYYY'),
'League 2',
46, 19, 9, 18, 63, 61, 66,
11, null
);
-- 2016-17
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2017', 'DD-MON-YYYY'),
'League 2',
46, 20, 17, 9, 70, 43, 77,
4, 'Lost in Promotion Play-Off Semi-Final'
);
-- 2017-18
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2018', 'DD-MON-YYYY'),
'League 2',
46, 25, 13, 8, 94, 46, 88,
2, 'Promoted'
);
commit;
select season_end_date, competition, finishing_position, notes
from luton_seasons
order by season_end_date
/
SEASON_END_DATE COMPETITION FINISHING_POSITION NOTES
--------------- ----------- -------------------- ----------------------------------------
01-JUN-2014 Conference 1 Promoted back to the Football League !
01-JUN-2015 League 2 8
01-JUN-2016 League 2 11
01-JUN-2017 League 2 4 Lost in Promotion Play-Off Semi-Final
01-JUN-2018 League 2 2 Promoted
5 rows selected. …until we try to insert a record for which a partition does not exist…
-- 2018-19
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2019', 'DD-MON-YYYY'),
'League 1',
46, 27, 13, 6, 90, 42, 94,
1, 'Champions ! Promoted to The Championship'
);
…when we are met with :
ORA-14400: no partition found in table MIKE.LUTON_SEASONS for inserted partition key "2019-06-01T00:00:00"
Wouldn’t it be good if we could just get Oracle to create partitions automatically, as and when they were needed ? Well, we can…
Creating an Interval Partitioned Table.We’re going to re-create the table, but this time, we’re going to use Interval Partitioning :
drop table luton_seasons;
create table luton_seasons
(
season_end_date date,
competition varchar2(25),
games_played number,
games_won number,
games_drawn number,
games_lost number,
goals_for number,
goals_against number,
points number,
finishing_position number,
notes varchar2(4000)
)
partition by range( season_end_date)
interval (numtoyminterval(1, 'year'))
(
partition season_2013_14 values less than (to_date('01-JUL-2014', 'DD-MON-YYYY'))
)
/
We’re still partitioning by range. However, we’re now specifying an interval, in this case 1 year.
For now though, our chances of avoiding ORA-14400 don’t look good as we’ve only created one partition :
select partition_name, high_value
from user_tab_partitions
where table_name = 'LUTON_SEASONS'
order by 1;
PARTITION_NAME HIGH_VALUE
-------------------- ------------------------------------------------------------------------------------------
SEASON_2013_14 TO_DATE(' 2014-07-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
Side Note – In 23c Oracle have added HIGH_VALUE_CLOB and HIGH_VALUE_JSON to USER_TAB_PARTITIONS so you can access the partition HIGH_VALUE via a datatype that is more malleable than the LONG HIGH_VALUE column that’s been in this view since David Pleat was last Luton manager.
Anyhow, let’s give it a go :
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2014', 'DD-MON-YYYY'),
'Conference',
46, 30, 11, 5, 102, 35, 101,
1, 'Promoted back to the Football League !'
);
-- 2014-15
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2015', 'DD-MON-YYYY'),
'League 2',
46, 19, 11, 16, 54, 44, 68,
8, null
);
-- 2015-16
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2016', 'DD-MON-YYYY'),
'League 2',
46, 19, 9, 18, 63, 61, 66,
11, null
);
-- 2016-17
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2017', 'DD-MON-YYYY'),
'League 2',
46, 20, 17, 9, 70, 43, 77,
4, 'Lost in Promotion Play-Off Semi-Final'
);
-- 2017-18
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2018', 'DD-MON-YYYY'),
'League 2',
46, 25, 13, 8, 94, 46, 88,
2, 'Promoted'
);
-- 2018-19
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2019', 'DD-MON-YYYY'),
'League 1',
46, 27, 13, 6, 90, 42, 94,
1, 'Champions ! Promoted to The Championship'
);
-- 2019-20
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2020', 'DD-MON-YYYY'),
'Championship',
46, 14, 9, 23, 54, 82, 15,
19, null
);
-- 2020-21
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2021', 'DD-MON-YYYY'),
'Championship',
46, 17, 11, 18, 41, 52, 62,
12, null
);
-- 2021-22
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2022', 'DD-MON-YYYY'),
'Championship',
46, 21, 12, 13, 63, 55, 75,
6, 'Lost in Promotion Play-Off Semi-Final'
);
-- 2022-23
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2023', 'DD-MON-YYYY'),
'Championship',
46, 21, 17, 8, 57, 39, 80,
3, 'Won Play-Off Final and promoted to Premiership !'
);
commit;
Oh look, that all worked :
…and the new partitions have been created automatically…
exec dbms_stats.gather_table_stats(user, 'LUTON_SEASONS');
select partition_name, high_value, num_rows
from user_tab_partitions t
where table_name = 'LUTON_SEASONS'
order by partition_position
/
We can further confirm that a particular partition holds just one record. For example :
select season_end_date, competition, finishing_position
from luton_seasons partition (SYS_P996);
…or, as we’re partitioning by date…
select season_end_date, competition, finishing_position
from luton_seasons partition for (to_date ('31-MAY-2019', 'DD-MON-YYYY'));
…confirms a single row in the partition…
SEASON_END_DATE COMPETITION FINISHING_POSITION ------------------------------ ---------------- ------------------ 01-JUN-2019 League 1 1 1 row selected.Interval Partitioining Clairvoyance
Now, you’re probably thinking that Interval partitioning will ensure that your table is equi-partitioned in terms of time periods, provided the value of the partition key is inserted sequentially.
But what happens if you enter dates out-of-sequence ?
For example :
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2025', 'DD-MON-YYYY'),
'Premier League',
38, 38, 0, 0, 112, 7, 114,
1, 'Clean sweep of trophies and a perfect season in one go !'
);
insert into luton_seasons
(
season_end_date,
competition,
games_played, games_won, games_drawn, games_lost, goals_for, goals_against, points,
finishing_position, notes
)
values
(
to_date('01-JUN-2024', 'DD-MON-YYYY'),
'Premier League',
38, 20, 10, 8, 64, 40, 70,
4, 'Champions League here we come !'
);
commit;
Now, you might think that Oracle would create the partition for values less than 01-JUL-2025 on the creation of the first record and then assign the second record to that partition as it already exists.
However, it’s actually smart enough to create the “missing” partition for the second insert :
select season_end_date, competition, finishing_position
from luton_seasons partition for (to_date ('01-JUN-2024', 'DD-MON-YYYY'))
order by 1;
SEASON_END_DATE COMPETITION FINISHING_POSITION
------------------------------ ------------------- ------------------
01-JUN-2024 Premier League 4
1 row selected.
We can see that the table’s last partition by position has a lower system-generated number in it’s name than it’s predecessor, indicating that it was created first :
select partition_name, partition_position, high_value
from user_tab_partitions
where table_name = 'LUTON_SEASONS'
order by partition_position;
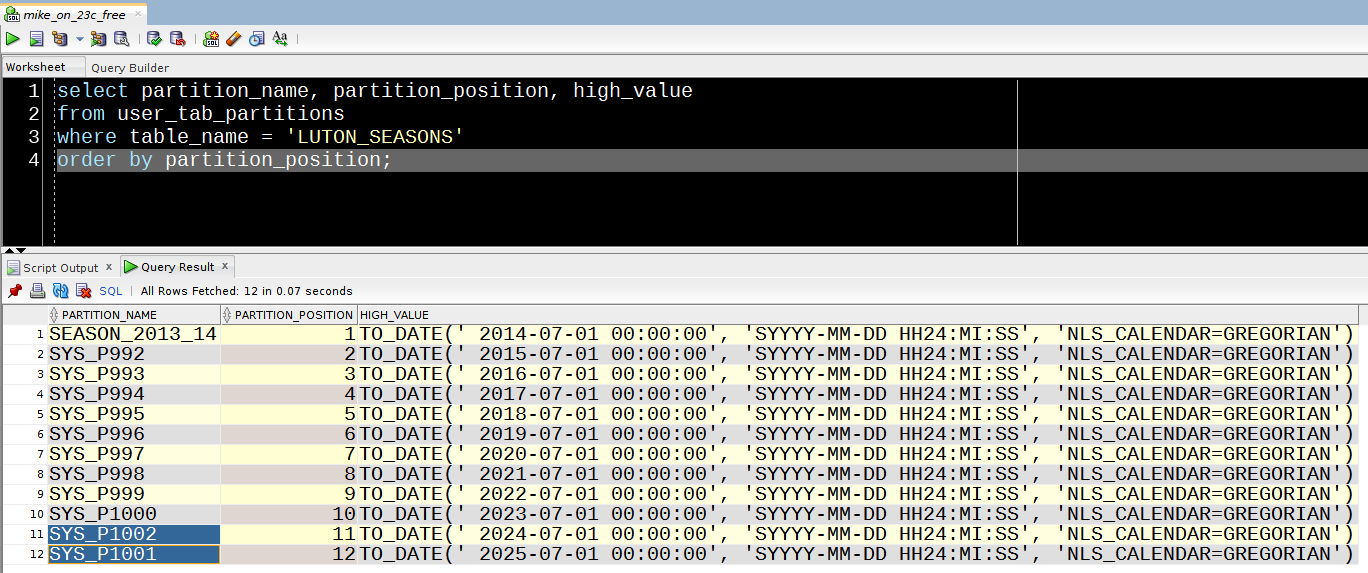 The Interval Functions
The Interval Functions
There are two functions that you can use when specifying an interval for your partitions :
Despite the camel-case formatting of these function names they are in-fact case insensitive when being used in SQL or PL/SQL.
NumToYMInterval lets you specify an interval in either ‘YEARS’ or ‘MONTHS’ :
select to_date('29-FEB-2020', 'DD-MON-YYYY') + numtoyminterval(4, 'year') as next_leap_year_day
from dual;
NEXT_LEAP_YEAR_DAY
------------------------------
29-FEB-2024
select to_date('01-JUL-2023', 'DD-MON-YYYY') + numtoyminterval(3, 'month') as start_q4_2023
from dual;
START_Q4_2023
------------------------------
01-OCT-2023
NumToDSInterval
NumToDSInterval allows you to specify more granular intervals – i.e :
- DAY
- HOUR
- MINUTE
- SECOND
How long is a football match ?
select numToDSInterval(5400, 'second') as match_length
from dual;
select numtodsinterval(90, 'minute') as match_length
from dual;
select numToDSInterval(1.5, 'hour') as match_length
from dual;
select numtodsinterval(1.5/24, 'day') as match_length
from dual;
Each of these queries return :
MATCH_LENGTH
------------------------------
+00 01:30:00.000000
Note that I’ve included the FROM clause in the above queries because, until the full 23c release sees the light of day, we’ll still need to use it in the day job.
Whatever you’re planning to do to pass the time until …
alter session set nls_date_format='DD-MON-YYYY HH24:MI';
select
to_date('12-AUG_2023', 'DD-MON-YYYY') + numtodsinterval(15, 'hour') as kick_off
from dual;
…using interval partitioning means that it should involve less manual partition creation.
The Oracle Database Features Site – reducing Oracle Documentation Drudgery
If there’s one thing Teddy approves of it’s eating you’re own Dog Food…although, he does appreciate the value of a varied diet…

Some nameless heroes in the Oracle Documentation Team seem to agree and have produced a publicly available APEX application which allows you to search:
- the features available in each successive Oracle release
- the various licensing options and packs available with each Edition
Time to head on over to the Oracle Database Features site and take a closer look…
FeaturesI’ve heard a fair bit about schema only accounts. I wonder when they came along ?
It looks like they have been around since 18c with further enhancements in later releases.
If I want details on a particular listing, I can just click on the title :
As you can see, there’s also a link to the relevant documentation.
It’s also possible to do a less specific search. For example, if I’m looking to upgrade from 11.2 to 19c and I want to see all of the new features in all of the intermediate releases :
The application also allows you to focus on areas of interest.
For example, If I want to see what’s new in 21c as far as Analytic Functions are concerned,
I can choose Data Warehousing/Big Data as my focus area then further refine my search by specifying Analytic Functions as the Sub Area of Interest.
Together with checking 21c as the Version and that I’m interested in New features only, the Application returns this :
 Limitations
Limitations
It’s worth noting that the information in this application is based on the New Features documentation for the respective Oracle versions. Therefore, whilst you’ll find an entry for the VALIDATE_CONVERSION SQL function, introduced in 12.1…
 Licensing
Licensing
Selecting the Licensing tab reveals functionality for navigating the often complex area of Oracle Licensing.
For example, if we want to find out which Editions Partitioning is available on :
Once again, further details are available by clicking on the title of a result row :

The Oracle Database Features site is a welcome augmentation to the existing documentation.
It’s categorised and searchable content offer the potential for significant saving in time and effort, especially when you’re preparing to move between Oracle versions.
The Ultimate Question of Life, the Universe, and… how big is my Oracle Table ?
At a time when the debate rages about how much you should trust what AI tells you, it’s probably worth recalling Deep Thought’s wildly incorrect assertion that the answer to the Ultimate Question of Life, the Universe, and Everything is forty-two.
As any Database specialist will know, the answer is the same as it is to the question “How big is my Oracle Table ?” which is, of course, “It depends”.
What it depends on is whether you want to know the volume of data held in the table, or the amount of space the database is using to store the table and any associated segments (e.g. indexes).
Connecting to my trusty Free Tier OCI Oracle Instance ( running 19c Enterprise Edition), I’ve set out on my journey through (disk) space to see if I can find some more definitive answers…
How big is my table in terms of the raw data stored in it ?Before going any further, I should be clear on the database language settings and character set that’s being used in the examples that follow. Note particularly that I’m not using a multi-byte character set :
select parameter, value from gv$nls_parameters order by parameter / PARAMETER VALUE ------------------------------ ------------------------------ NLS_CALENDAR GREGORIAN NLS_CHARACTERSET AL32UTF8 NLS_COMP BINARY NLS_CURRENCY £ NLS_DATE_FORMAT DD-MON-YYYY NLS_DATE_LANGUAGE ENGLISH NLS_DUAL_CURRENCY € NLS_ISO_CURRENCY UNITED KINGDOM NLS_LANGUAGE ENGLISH NLS_LENGTH_SEMANTICS BYTE NLS_NCHAR_CHARACTERSET AL16UTF16 NLS_NCHAR_CONV_EXCP FALSE NLS_NUMERIC_CHARACTERS ., NLS_SORT BINARY NLS_TERRITORY UNITED KINGDOM NLS_TIMESTAMP_FORMAT DD-MON-RR HH24.MI.SSXFF NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH24.MI.SSXFF TZR NLS_TIME_FORMAT HH24.MI.SSXFF NLS_TIME_TZ_FORMAT HH24.MI.SSXFF TZR 19 rows selected.
Now, let see if we can work out how much raw data is held in a table.
We’ll start with a very simple example :
create table marvin as
select 1000 + rownum as id
from dual
connect by rownum <= 1024;
Marvin may have a brain the size of a planet but his tabular namesake has more modest space requirements.
It’s 1024 records are all 4 digits long.
Therefore, the size of the table data should be 4096 bytes, right ?
“Hang on”, your thinking, “why not just lookup the size in USER_SEGMENTS and make this a really short post ?”
Well :
select bytes
from user_segments
where segment_name = 'MARVIN'
and segment_type = 'TABLE'
/
BYTES
----------
65536
USER_SEGMENTS will give you a size in bytes, but it’s not the same as the amount of raw data.
We’ll come back to this in a bit.
For now though, we can cross-check the size from elsewhere in the data dictionary, provided the stats on the table are up-to-date.
To ensure that this is so, I can run :
exec dbms_stats.gather_table_stats('MIKE', 'MARVIN');
This will ensure that statistics data is populated in the USER_TABLES view. This means that we can estimate the data volume by running the following query :
select num_rows, avg_row_len,
num_rows * avg_row_len as data_in_bytes
from user_tables
where table_name = 'MARVIN'
/
…which returns…
NUM_ROWS AVG_ROW_LEN DATA_IN_BYTES
---------- ----------- -------------
1024 4 4096
That looks promising.
We can further verify this by running :
select sum(length(id)) as data_in_bytes
from marvin
/
DATA_IN_BYTES
-------------
4096
OK, now let’s see what happens with a slightly more complex data set, and an index as well …
create table hitchikers
(
id number generated always as identity,
character_name varchar2(250),
quote varchar2(4000),
constraint hitchikers_pk primary key (id)
)
/
declare
procedure ins( i_character in varchar2, i_quote in varchar2)
is
begin
insert into hitchikers( character_name, quote)
values(i_character, i_quote);
end;
begin
for i in 1..1024 loop
ins('Deep Thought', 'Forty-Two');
ins('Trillian', q'[we have normality... anything you can't cope with is, therefore, your own problem]');
ins('Ford Prefect', 'Time is an illusion. Lunchtime doubly so.');
ins('Zaphod Beeblebrox', q'[If there's anything more important than my ego around, I want it caught and shot right now!]');
ins(null, 'Anyone who is capable of getting themselves made President should on no account be allowed to do the job');
ins('Marvin', q'[Life! Loathe it or hate it, you can't ignore it.]');
ins('Arthur Dent', 'This must be Thursday. I never could get the hang of Thursdays');
ins('Slartibartfast', q'[I'd rather be happy than right any day]');
end loop;
commit;
end;
/
commit;
Once stats are present on the table, we can check the expected data size as before :
select num_rows, avg_row_length,
num_rows * avg_row_length as data_in_bytes
from user_tables
where table_name = 'HITCHIKERS'
/
NUM_ROWS AVG_ROW_LEN DATA_IN_BYTES
---------- ----------- -------------
8192 75 614400
This time, the size in bytes figure we get back is not exact, as we can confirm with :
select
sum( length(id) +
nvl(length(character_name),0) +
nvl(length(quote), 0)) as data_in_bytes
from hitchikers
/
DATA_IN_BYTES
-------------
598957
To verify the actual size in bytes, we can dump the contents of a table into a csv file. In this case, I’m using SQLDeveloper :

The resulting file is a different size again :
ls -l hitchikers.csv -rw-rw-r-- 1 mike mike 656331 May 13 11:50 hitchikers.csv
This can be accounted for by the characters added as part of the csv formatting.
First, the csv file includes a header row :
head -1 hitchikers.csv "ID","CHARACTER_NAME","QUOTE"
Including the line terminator this is 30 bytes :
head -1 hitchikers.csv |wc -c
30
The format in each of the 8192 data rows includes :
- a comma after all but the last attribute on a row
- a line terminator after the last attribute
- double quotes enclosing each of the two VARCHAR attributes.
For example :
grep ^42, hitchikers.csv
42,"Trillian","we have normality... anything you can't cope with is, therefore, your own problem"
That’s a total of 7 extra bytes per data row.
Add all that up and it comes to 57374 bytes which are a consequence of csv formatting.
Subtract that from the file size and we get back to the calculated data size we started with :
656331 - 57374 = 598957
This confirms that the figures in USER_TABLES are approximate and you’ll need to bear this in mind if you’re relying on them to calculate the size of the data in a table.
Whilst were here, let’s see what effect compression might have on our ability to determine the raw data size.
We can do this by creating a table that has the same structure as HITCHIKERS and contains the same data, but which is compressed :
create table magrathea
(
id number,
character_name varchar2(250),
quote varchar2(4000),
constraint magrathea_pk primary key (id)
)
row store compress advanced
/
insert into magrathea( id, character_name, quote)
select id, character_name, quote
from hitchikers
/
commit;
exec dbms_stats.gather_table_stats(user, 'MAGRATHEA');
It turns out that, for the purposes of our raw data calculation, the effect of table compression is…none at all :
select num_rows, avg_row_len,
num_rows * avg_row_len
from user_tables
where table_name = 'MAGRATHEA'
/
NUM_ROWS AVG_ROW_LEN NUM_ROWS*AVG_ROW_LEN
---------- ----------- --------------------
8192 75 614400
However, if you look at the number of blocks used to store the table, the effects of compression are more evident :
select table_name, blocks
from user_tables
where table_name in ('HITCHIKERS', 'MAGRATHEA')
order by 2
/
TABLE_NAME BLOCKS
------------------------------ ----------
MAGRATHEA 20
HITCHIKERS 95
Incidentally, it’s worth noting that, as with the data size, the number of blocks reported in USER_TABLES are somewhat approximate.
USER_SEGMENTS reports the number of blocks for each table as :
select segment_name, blocks
from user_segments
where segment_name in ('HITCHIKERS', 'MAGRATHEA')
order by 2
/
SEGMENT_NAME BLOCKS
------------------------------ ----------
MAGRATHEA 24
HITCHIKERS 104
So it looks like compression will affect the amount of database space required to store an object but not the size of the actual data. This brings us nicely on to…
How big is my table in terms of the amount of space it’s taking up in the database ?Let’s go back to MARVIN. Remember, this table contains 4K of raw data, but USER_SEGMENTS claims that it’s quite a bit larger :
select bytes
from user_segments
where segment_name = 'MARVIN'
and segment_type = 'TABLE'
/
BYTES
----------
65536
To understand how Oracle has come up with this figure, you need to consider that :
- the smallest unit of space that Oracle addresses is measured in blocks
- the size of these blocks is defined at tablespace level.
- any object that uses space is allocated that space in units of an extent – which is a number of contiguous blocks.
If we take a look at MARVIN, we can see that the table resides in the DATA tablespace and has been allocated a single extent of 8 blocks :
select tablespace_name, bytes, blocks, extents from user_segments where segment_name = 'MARVIN'; TABLESPACE_NAME BYTES BLOCKS EXTENTS ------------------------------ ---------- ---------- ---------- DATA 65536 8 1
The block size is defined at the tablespace level and is held in USER_TABLESPACES in bytes :
select block_size
from user_tablespaces
where tablespace_name = 'DATA';
BLOCK_SIZE
----------
8192
If we now multiply the number of blocks in the table by the size of those blocks, we get back to the size that USER_SEGMENTS is reporting :
select seg.blocks * tsp.block_size
from user_segments seg
inner join user_tablespaces tsp
on seg.tablespace_name = tsp.tablespace_name
where seg.segment_name = 'MARVIN';
SEG.BLOCKS*TSP.BLOCK_SIZE
-------------------------
65536
MARVIN is a table with no ancillary segments, such as indexes.
To find the total space being used for the HITCHIKERS table, we’ll also need to consider the space being taken up by it’s index, HITCHIKERS_PK :
select seg.segment_name, seg.segment_type, seg.blocks, ts.block_size,
seg.bytes
from user_segments seg
inner join user_tablespaces ts
on ts.tablespace_name = seg.tablespace_name
where seg.segment_name in ('HITCHIKERS', 'HITCHIKERS_PK')
/
SEGMENT_NAME SEGMENT_TYPE BLOCKS BLOCK_SIZE BYTES
-------------------- --------------- ---------- ---------- ----------
HITCHIKERS TABLE 104 8192 851968
HITCHIKERS_PK INDEX 24 8192 196608
…in other words…
select sum(seg.bytes)
from user_segments seg
where seg.segment_name in ('HITCHIKERS', 'HITCHIKERS_PK')
/
SUM(SEG.BYTES)
--------------
1048576
On the subject of ancillary segments, what about LOBS ?
create table the_guide(
id number generated always as identity,
message clob);
declare
v_msg clob;
begin
for i in 1..1000 loop
v_msg := v_msg||q'[Don't Panic!]';
end loop;
insert into the_guide(message) values( v_msg);
end;
/
commit;
Unlike other segment types, LOBSEGMENT and LOBINDEX segments do not have their parent tables listed as the SEGMENT_NAME in USER_SEGMENTS.
Therefore, we need to look in USER_LOBS to identify it’s parent table for a LOBSEGMENT and USER_INDEXES for a LOBINDEX :
select segment_name, segment_type, bytes, blocks
from user_segments
where(
segment_name = 'THE_GUIDE'
or
segment_name in (
select segment_name
from user_lobs
where table_name = 'THE_GUIDE'
)
or
segment_name in (
select index_name
from user_indexes
where table_name = 'THE_GUIDE'
)
)
/
SEGMENT_NAME SEGMENT_TYPE BYTES BLOCKS
------------------------------ --------------- ---------- ----------
THE_GUIDE TABLE 65536 8
SYS_IL0000145509C00002$$ LOBINDEX 65536 8
SYS_LOB0000145509C00002$$ LOBSEGMENT 1245184 152
In this instance, although the table segment itself is only taking up 65536 bytes, when you add in all of the supporting objects, the total space requirement increases to 1376256 bytes.
If you’ve managed to make this far then meet me at the Big Bang Burger Bar for a Pan Galactic Garble Blaster. I need a drink after that.
(You Gotta) Fight for Your Right (To Query !) – the easy way to use External Tables with CSV files
Since the days when dinosaurs roamed the Earth – and I realised that programming was indoor work with little physical effort – the CSV file has been an ETL workhouse in the world of Data Warehousing.
In the case of Oracle, working with CSVs is somewhat simplified by the use of External Tables.
That’s not to say there aren’t challenges, especially when things don’t quite go as expected and you have to wade through various operating system files looking for exactly why some or all of the records in a file have not been loaded.
As enthusiastic as I am about the joys of the linux command-line, the prospect of grappling with sed, awk and regexp to diagnose data issues does not appeal.
I’d much rather use SQL. After all, that’s what it’s designed for.
Fortunately, for me, external tables make it relatively simple to upload the contents of a text file directly into a database table, from where SQL can be used to :
- validate the structure and contents of the file
- transform the data into it’s target data types
- identify any problems with the data we’ve received
As you may have guessed from the title (and the age of the author), the data we’re using has a bit of a Beastie Boys theme.
We have a file containing details of Beastie Boys singles that have charted in the UK :
row_type,track_name,peak_chart_position,album,release_date "","She's On It",10,,19860912, "","(You Gotta) Fight for Your Right (To Party!)",11,"Licensed to Ill",, "","No Sleep till Brooklyn",14,"Licensed to Ill",19870301, "","Girls",34,"Licensed to Ill",19870506, "","Hey Ladies",76,"Paul's Boutique",19890725, "","Pass the Mic",47,"Check Your Head",19920407, "","Jimmy James",55,"Check Your Head",19920828, "","Sabotage",19,"Ill Communication",19940128, "","Sure Shot",27,"Ill Communication",19940602, "","Intergalactic",5,"Hello Nasty",19980602, "","Remote Control/Three MC's and One DJ",21,"Hello Nasty",19990123 "","Alive",28,,, "","Ch-Check It Out",8,"To the 5 Boroughs",20040503, "","Triple Trouble",37,"To the 5 Boroughs",, "","An Open Letter to NYC",38,"To the 5 Boroughs",, "TRAILER",15
I want to load this data into my application tables on an Oracle 19c database.
One thing that often gets overlooked when considering a CSV file is that, whatever datatype the fields started out as (or indeed, are intended to end up as), in the file they are all merely text strings.
This can make the design of the external table we’re using to read this file quite simple in terms of datatypes…
create table beastie_xt (
row_type varchar2(4000),
track_name varchar2(4000),
peak_chart_position varchar2(4000),
album varchar2(4000),
release_date varchar2(4000)
)
organization external (
type oracle_loader
default directory dbshare
access parameters (
fields csv without embedded
missing field values are null
reject rows with all null fields
)
location('beastie.csv')
)
reject limit unlimited
/
Note that using the csv keyword in the access parameters clause, causes the external table to assume that the delimiter character is a “,” and that fields may be enclosed by double-quotes (“)
If we test the table now, we can see that all of the rows in the file are loaded, including the header and trailer records :
 I can’t believe “Sabotage” only got to 19
The ETL Process
I can’t believe “Sabotage” only got to 19
The ETL Process
Now, we could do all of our data interrogation and manipulation using the external table. However, each time the table is queried, the file is read in it’s entirety and the fact recorded in the external table’s associated logfile.
As well as being a bit slow for large files, this does cause the logfile to grow rather rapidly.
As an alternative to this then, I’m going to use the external table only to read the file as it’s contents is loaded into a permanent database segment :
create table beastie_stg(
file_name varchar2(500),
file_row_number number,
row_type varchar2(4000),
track_name varchar2(4000),
peak_chart_position varchar2(4000),
album varchar2(4000),
release_date varchar2(4000))
/
insert into beastie_stg
select
'beastie.csv' as file_name,
rownum as file_row_number,
row_type,
track_name,
peak_chart_position,
album,
release_date
from beastie_xt
/
commit;
Now we have our data in a permanent segment, we can validate and load it into the application proper.
Remember, because both our External Table and Staging table definitions are quite permissive, we can load the entire file, including it’s header and trailer records.
To start with, let’s check that the file contains the all of the fields we expect, in the order in which we expect them :
-- Expected ordered field list
select listagg( lower(column_name), ',') within group( order by column_id)
from user_tab_columns
where table_name = 'BEASTIE_XT'
minus
-- Actual ordered field list
select
row_type
||','||track_name
||','||peak_chart_position
||','||album
||','||release_date
from beastie_stg
where row_type = 'row_type';
If this query returns any rows then there is a mismatch between the header record and what we’re expecting so we’ll want to investigate.
In this instance though, we’re OK.
Next we need to make sure that we’ve received all of the data records. We can see that the trailer record is saying we should have 15 data records in the file. Note that, because we’re still treating everything as a string, the count in the trailer record is actually in the TRACK_NAME column of our staging table :
select track_name as data_record_count from beastie_stg where row_type = 'TRAILER' and file_name = 'beastie.csv'; DATA_RECORD_COUNT ------------------ 15
We can verify this by simply counting the records that we’ve staged, excluding the header and trailer…
select count(*)
from beastie_stg
where row_type is null
and file_name = 'beastie.csv'
/
COUNT(*)
----------
15
Finally, we can load our data records into our core table, converting them to their target datatypes in the process.
The core table looks like this :
create table beastie_core (
file_name varchar2(500),
file_row_number number,
track_name varchar2(500),
peak_chart_position number,
album varchar2(500),
release_date date)
/
If we want to load all of the valid records whilst handling any that we cannot transform correctly, there are several options available. In this case we’re going to use an error logging table.
To create the error logging table itself…
exec dbms_errlog.create_error_log('beastie_core');
Now we can populate the core application table using the LOG ERRORS clause to direct any failing records to the error table :
insert into beastie_core
select
file_name,
file_row_number,
track_name,
to_number(peak_chart_position) as peak_chart_position,
album,
to_date(release_date, 'YYYYMMDD')
from beastie_stg
where row_type is null -- just load the data records
log errors('beastie.csv')
reject limit unlimited
/
commit;
Once the core load is completed, we can check that we’ve loaded all of the records…
select count(*)
from beastie_core
where file_name = 'beastie.csv';
COUNT(*)
----------
15
…and confirm that there are no errors…
select count(*)
from err$_beastie_core
where ora_err_tag$ = 'beastie.csv';
COUNT(*)
----------
0
Our file has been successfully validated and loaded, all without the need for any fiendishly clever regular expressions.
Loading data into Oracle directly from compressed or enrcypted files
Whilst it’s not uncommon to transfer data between systems by means of text files, the files themselves often turn-up in a binary format.
They may have been compressed or even encrypted before transit.
Turning them back into text so that they can be processed may be a bit of an overhead.
Not only can you end up with two copies of the data ( the binary original and the re-constituted text version), the process of conversion may be both time consuming and resource intensive.
In the case of encrypted files, persisting the unencrypted data in a file may have additional security implications.
Fortunately, it’s possible to load data from such binary formatted files into Oracle without first having to write it to a text file.
Irrespective of whether your incoming feed file is enrcypted or merely compressed, loading it into Oracle should be effortless for you after reading this.
You need not worry about any potential pitfalls because I’ve already fallen into each pit in turn, as I shall now recount.
To start with, I’ll be looking at how to use an External Table Preprocessor to load data from a compressed file.
I’ll then go through loading data that’s GPG encrypted.
Following that, we’ll take a look at why PDB_OS_CREDENTIAL might not be the help you hoped it might be when dealing with GPG decryption and how SQL*Loader can help.
Whilst I was writing this, Oracle considerately released 23c Free and made it available in a VirtualBox appliance running Oracle Linux Server 8.7, so it’d be rude not to use it for the examples that follow…
SetupTo start with I’ve created a new OS user called app_user and a group called app_os.
I’ve made this the primary group for app_user as well as adding oracle to the group.
sudo useradd -m app_user
sudo groupadd app_os
sudo usermod -g app_os app_user
sudo usermod -a -G app_os oracle
NOTE – for this change to take effect for oracle, I had to restart the VM.
Next, I’ve created some directories under the app_user home and granted appropriate permissions.
The app_user home is visible to the group :
cd $HOME ls -ld drwxr-x---. 7 app_user app_os 180 Apr 8 11:55 .
The bin directory will hold any shell scripts we need to execute.
The upload directory will hold feed files to be loaded into the database.
Note that oracle will have access to execute these through the group, but will not be able to write to them :
drwxr-x---. 2 app_user app_os 27 Apr 8 12:16 bin drwxr-x---. 2 app_user app_os 50 Apr 9 10:36 upload
Finally, we have a directory to hold any log files generated. Obviously, oracle does need write access to this directory :
drwxrwx---. 2 app_user app_os 54 Apr 8 14:09 logs
In the Database, I’ve created directory objects on each of these directories.
Note that home on Oracle Linux Server is a symbolic link to /opt/oracle/userhome, so we need to use the physical path in the Directory Object definition :
create or replace directory app_bin as '/opt/oracle/userhome/app_user/bin'
/
create or replace directory app_log as '/opt/oracle/userhome/app_user/logs'
/
create or replace directory app_upload as '/opt/oracle/userhome/app_user/upload'
/
…and granted the appropriate permissions to the HR database user :
grant read, execute on directory app_bin to hr;
grant read, write on directory app_log to hr;
grant read on directory app_upload to hr;
I’ve created a csv file containing all of the records in the employees table.
In SQLCL this is accomplished by connecting to the database as HR and running :
set sqlformat csv
spool employees.csv
select 'DATA' as row_type,
emp.*
from employees
/
spool off
I’ve also tweaked the row count at the end of the file to make it look like a trailer record you might expect to see on a feed file…
TRA,107Coming gundun with gunzip
I’ve got a compressed version of the file in the uploads directory :
-rw-r--r--. 1 app_user app_os 3471 Apr 9 10:36 employees.csv.gz
Now I need to create a simple shell script to call from an external table preprocessor to unzip the file on the fly and send the output to STDOUT. This will then be read and uploaded into the external table automatically.
The script is called unzip_file.sh and, initially, it looks like this :
#!/usr/bin/sh
/usr/bin/gunzip -c $1
When invoked by an external table preprocessor call, the script will be passed the fully qualified path of the file specified as the location of the external table.
The permissions on the script are :
-rwxr-x---. 1 app_user app_os 198 Apr 8 13:04 unzip_file.sh
Now for the external table itself. This is called employees_zip_xt and is created in the HR schema :
create table employees_zip_xt
(
row_type varchar2(10),
employee_id number,
first_name varchar2(20),
last_name varchar2(25),
email varchar2(25),
phone_number varchar2(20),
hire_date date,
job_id varchar2(10),
salary number,
commission_pct number,
manager_id number,
department_id number
)
organization external
(
type oracle_loader
default directory app_upload
access parameters
(
records delimited by newline
logfile app_log : 'employees_zip_xt.log'
badfile app_log : 'employees_zip_xt.bad'
nodiscardfile
preprocessor app_bin : 'unzip_file.sh'
skip 1
load when row_type = 'DATA'
fields terminated by ',' optionally enclosed by '"'
missing field values are null
(
row_type char(10),
employee_id integer external(6),
first_name char(20),
last_name char(25),
email char(25),
phone_number char(20),
hire_date date "DD-MON-RR",
job_id char(10),
salary float external,
commission_pct float external,
manager_id integer external(6),
department_id integer external(4)
)
)
location('employees.csv.gz')
)
reject limit unlimited
/
The table will process the data written to STDOUT by the preprocessor script.
Hmmm, I wonder what that suspicious clump of leaves and twigs is covering…
select * from employees_zip_xt; ORA-29913: error while processing ODCIEXTTABLEFETCH routine ORA-29400: data cartridge error KUP-04095: preprocessor command /opt/oracle/userhome/app_user/bin/unzip_file.sh encountered error "/usr/bin/gunzip: line 57: /opt/oracle/product/23c/dbhomeFree/dbs/gzip: No such file or directory
Give me a hand up, will you ?
As well as the ever inscrutable ODCIEXTTABLEFETCH, we have KUP-04095 complaining that it can’t find an executable that we haven’t called.
Whilst we’ve specified the full path to the gunzip executable in our script, GNU gunzip calls gzip during execution. Because that doesn’t use a fully qualified path, it looks in the wrong place.
The solution then, is to set the PATH environment variable in our script…
#!/usr/bin/sh
# Need the PATH specified because gunzip executable is calling gzip under the covers
export PATH=/usr/bin
gunzip -c $1
Now, when we query the table, it works as expected :

…and the unencrypted data is not persisted in a file…
ls -l emp* -rw-r--r--. 1 app_user app_os 3471 Apr 9 10:36 employees.csv.gz
Now we’ve established the concept, let’s try something a little more ambitious…
Where did I leave my keys ?Just for a change, I’m going to start with the example that actually works as expected.
I’ve generated GPG keys for oracle and used the public key to encrypt the original csv. The encrypted file has been moved to the upload directory :
ls -l *.gpg -rw-r--r--. 1 app_user app_os 3795 Apr 9 12:31 employees.csv.gpg
Note that the passphrase has been saved in passphrase.txt in oracle‘s home directory with the following permissions :
ls -l passphrase.txt -rw-------. 1 oracle oracle 19 Apr 9 15:41 passphrase.txt
Now we need a script in our bin directory to decrypt the file (decrypt_file.sh) :
#!/usr/bin/sh
/usr/bin/gpg \
--decrypt \
--pinentry-mode loopback \
--passphrase-file /opt/oracle/userhome/oracle/passphrase.txt \
--batch $1 2>/dev/null
We have a new external table – employees_enc_xt, which may look somewhat familiar :
create table employees_enc_xt
(
row_type varchar2(10),
employee_id number,
first_name varchar2(20),
last_name varchar2(25),
email varchar2(25),
phone_number varchar2(20),
hire_date date,
job_id varchar2(10),
salary number,
commission_pct number,
manager_id number,
department_id number
)
organization external
(
type oracle_loader
default directory app_upload
access parameters
(
records delimited by newline
logfile app_log : 'employees_enc_xt.log'
badfile app_log : 'employees_enc_xt.bad'
nodiscardfile
preprocessor app_bin : 'decrypt_file.sh'
skip 1
load when row_type = 'DATA'
fields terminated by ',' optionally enclosed by '"'
missing field values are null
(
row_type char(10),
employee_id integer external(6),
first_name char(20),
last_name char(25),
email char(25),
phone_number char(20),
hire_date date "DD-MON-RR",
job_id char(10),
salary float external,
commission_pct float external,
manager_id integer external(6),
department_id integer external(4)
)
)
location('employees.csv.gpg')
)
reject limit unlimited
/
…as will the results when we query it :
 When oracle doesn’t own the private GPG key
When oracle doesn’t own the private GPG key
The point of a private GPG key is that it’s only accessible to the user that owns it. If that’s not oracle then we need to find a means of executing as the account which does own the key.
No biggie, the PDB_OS_CREDENTIAL parameter has that covered…oh, what have I stepped in.
PDB_OS_CREDENTIAL has been around since 12c and should allow you to specify the os user which runs when you invoke an external table preprocessor.
Coincidentally, the bug that causes this setting to be ignored has been around for a similar length of time.
I have personally confirmed this on versions 19c (splash !), 21c (squelch !) and now 23c (splat !).
I do hope that’s mud.
In these articles, Szymon Skorupinski does a marvellous job of explaining system behaviour both before and after the application of the patch to fix this issue :
If applying the patch is going to be problematic, not least because of the regression testing effort required to make sure none of your existing code breaks, then you do have an alternative…
I should be able to scrape it off once it driesBefore external tables there was SQL*Loader. It’s still supported, which is just as well in this case as we can use it to run a script as the owner of the PGP key and load the data directly into a staging table in the database.
The advantage of this approach is that you can execute it as the owner of the GPG key (although I’m still using the oracle user in this example).
To start with, we need a table to stage the data into :
create table employees_stg
(
row_type varchar2(10),
employee_id number,
first_name varchar2(20),
last_name varchar2(25 ),
email varchar2(25),
phone_number varchar2(20),
hire_date date,
job_id varchar2(10),
salary number,
commission_pct number,
manager_id number,
department_id number
)
/
Now we create a SQL*Loader control file in the bin directory on the server (load_employees.ctl) :
options(skip=1)
load data
badfile '/opt/oracle/userhome/app_user/logs/load_employees.bad'
discardfile '/opt/oracle/userhome/app_user/logs/load_employees.dis'
append
into table employees_stg
when row_type='DATA'
fields terminated by "," optionally enclosed by '"'
trailing nullcols
(
row_type char(10),
employee_id integer external(6),
first_name char(20),
last_name char(25),
email char(25),
phone_number char(20),
hire_date date "DD-MON-RR",
job_id char(10),
salary float external,
commission_pct float external,
manager_id integer external(6),
department_id integer external(4)
)
Finally, we create script to perform the load (load_employees.sh) :
#!/usr/bin/sh
/usr/bin/gpg \
--decrypt \
--pinentry-mode loopback \
--passphrase-file /opt/oracle/userhome/oracle/passphrase.txt \
--batch \
/home/app_user/upload/employees.csv.gpg 2>/dev/null|sqlldr \
control=load_employees.ctl \
userid=connect_string \
log=/home/app_user/logs/load_employees.log \
data=\'-\'
…replacing connect_string with the connect string for the schema you’re loading into.
Incidentally, in order to avoid having a database password hard-coded in the script, an Oracle Wallet would come in handy here.
Note that we tell SQL*Loader to read it’s STDIN for the data by specifying :
data =\'-\'
When we run this, we can see that it works as expected :


You could easily automate this load process by creating a DBMS_SCHEDULER external job.
ConclusionAs we’ve seen, it’s perfectly possible to pipe data from binary format files into the database without having to persist it in plain text. However, if you do decide to go down this path, you may want to wear your wellies.
Loading selected fields from a delimited file into Oracle using an External Table
If you’ve dealt with ETL processes for any length of time, sooner or later, you’ll be faced with the need to load data from a delimited file into your database.
In the case of Oracle, External Tables are tailor-made for this purpose.
However, whilst they might make loading an entire file is very simple, exactly how do you persuade them to just load certain fields ?
What we’ll be looking at here is :
- an external table that loads an entire file
- an external table that just loads the first few fields of each record in the file
- an external table that loads a selection of fields that are not contiguous in the file
All of these examples have been tested on Oracle 21cXE, although I’ve not seen any behaviour here that’s not consistent with Oracle versions back to 11.2.
The example file is simply a csv (called employees.csv) containing all the records from the EMPLOYEES table in the HR sample schema.
The external table which reads the entire file is called ALL_EMPS_XT :
create table all_emps_xt(
employee_id number(6,0),
first_name varchar2(20),
last_name varchar2(25),
email varchar2(25),
phone_number varchar2(20),
hire_date date,
job_id varchar2(10),
salary number(8,2),
commission_pct number(2,2),
manager_id number(6,0),
department_id number(4,0))
organization external (
type oracle_loader
default directory my_files
access parameters (
records delimited by newline
logfile 'all_emps.log'
badfile 'all_emps.bad'
discardfile 'all_emps.dis'
skip 1
load when (1:3) != 'TRL'
fields terminated by ',' optionally enclosed by '"'
missing field values are null (
employee_id integer external(6),
first_name char(20),
last_name char(25),
email char(25),
phone_number char(20),
hire_date date "DD-MON-YYYY",
job_id char(10),
salary float external,
commission_pct float external,
manager_id integer external(6),
department_id integer external(4))
)
location('employees.csv')
)
reject limit unlimited
/
Sure enough, if we select from the external table, we can see that all of the fields have been populated as expected …
select *
from all_emps_xt
where job_id in ('AD_PRES', 'SA_MAN')
order by employee_id
/

… and that all 107 data records have been loaded :
select count(*) from all_emps_xt;
COUNT(*)
----------
107
Loading first few fields only
Let’s say that we weren’t interested in all of the fields in the file and we just wanted the first five – i.e. :
- EMPLOYEE_ID
- FIRST_NAME
- LAST_NAME
- PHONE_NUMBER
This is simple enough, we just specify definitions for those fields in the access parameters clause and our external table will ignore all of the fields after phone_number, simply by making sure that
missing field values are null
…is still specified in the access parameters clause of the External Table. This one is called START_EMPS_XT :
create table start_emps_xt(
employee_id number(6,0),
first_name varchar2(20),
last_name varchar2(25),
email varchar2(25),
phone_number varchar2(20))
organization external (
type oracle_loader
default directory my_files
access parameters (
records delimited by newline
logfile 'start_emps.log'
badfile 'start_emps.bad'
discardfile 'start_emps.dis'
skip 1
load when (1:3) != 'TRL'
fields terminated by ',' optionally enclosed by '"'
missing field values are null (
employee_id integer external(6),
first_name char(20),
last_name char(25),
email char(25),
phone_number char(20))
)
location('employees.csv')
)
reject limit unlimited
/
select *
from start_emps_xt
where employee_id between 100 and 110
order by employee_id
/
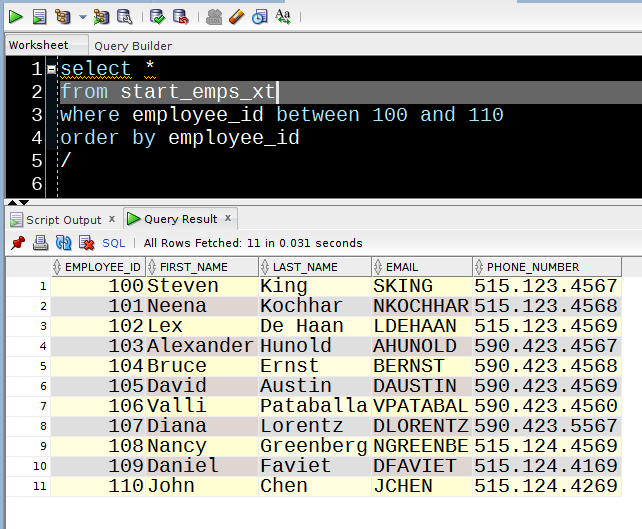 Selecting non-contiguous fields to load
Selecting non-contiguous fields to load
This is where it gets a bit more tricky…but not much, as it turns out. Say we want to load :
Field NoField Name1EMPLOYEE_ID2FIRST_NAME3LAST_NAME6HIRE_DATE10MANAGER_ID11DEPARTMENT_IDWe simply need to include placeholder values for in the access parameters clause for the columns we don’t want to load. In this case, I’ve used the actual field names but not specified a data type for them. That way, if I ever need to add one of these columns into the external table definition, I know where it appears in the file and the change is compartively simple. Anyhow, the table is called SELECTED_EMPS_XT :
create table selected_emps_xt(
employee_id number(6,0),
first_name varchar2(20),
last_name varchar2(25),
hire_date date,
manager_id number(6,0),
department_id number(4,0))
organization external (
type oracle_loader
default directory my_files
access parameters (
records delimited by newline
logfile 'selected_emps.log'
badfile 'selected_emps.bad'
discardfile 'selected_emps.dis'
skip 1
load when (1:3) != 'TRL'
fields terminated by ',' optionally enclosed by '"'
missing field values are null (
employee_id integer external(6),
first_name char(20),
last_name char(25),
email,
phone_number,
hire_date date "DD-MON-YYYY",
job_id,
salary,
commission_pct,
manager_id integer external(6),
department_id integer external(4))
)
location('employees.csv')
)
reject limit unlimited
/
Sure enough, if we query the table :
select *
from selected_emps_xt
where department_id = 60
order by hire_date
/

FORALL DML – why context isn’t everything
This post is the latest in an occasional series on the theme of stuff that doesn’t work quite how I thought it did.
It is the result of finding out the fun way that, rather than being “much faster” than using a humble Cursor For Loop , Bulk Collect/Forall for DML in PL/SQL can merely be a bit less slow.
Just in case my boss is reading this, I’d better get my excuses in right at the beginning.
This is what the Oracle PL/SQL Language Reference has to say about Forall :
A FORALL statement is usually much faster than an equivalent FOR LOOP statement. However, a FOR LOOP statement can contain multiple DML statements, while a FORALL statement can contain only one. The batch of DML statements that a FORALL statement sends to SQL differ only in their VALUES and WHERE clauses. The values in those clauses must come from existing, populated collections.
…and later in the same document ….
The FORALL statement runs one DML statement multiple times, with different values in the VALUES and WHERE clauses.
The different values come from existing, populated collections or host arrays. The FORALL statement is usually much faster than an equivalent FOR LOOP statement.
I’ll be testing that assertion in this post.
Using a simple test case, which involves performing different DML operations on different tables using a single record set, I’ll begin by comparing the relative performance of:
- simple SQL statements inside a PL/SQL block
- Cursor For Loops
- Bulk Collect/Forall operations
I’ll then explore the potential performance gains available using database objects such as VARRAYs and Global Temporary Tables to hold the array being used in the DML.
NOTE – If you want to run these tests yourself on your own environment/database version to validate these findings, you can find the scripts I’ve used here on my Github Repo.
Test ScenarioI have a single set of records that I want to use in an insert, an update and a delete.
Each of these operations has a different target table.
I’ve created a simple test case, using this script ( called setup.sql) :
clear screen
set serverout on size unlimited
drop table input_records;
drop table record_statuses;
drop table target_table;
create table input_records
as
select rownum as id
from dual
connect by rownum <=100000;
create table record_statuses
as
select id, 'WAITING' as status
from input_records;
create table target_table ( id number);
The tests have all been run on Oracle Enterprise Edition 19c, although the behaviour described here appears to be consistent across Oracle Database versions from 11g upwards.
I’ve run each script twice in succession and then taken the fastest runtime. This is to ensure I’ve not been caught out by the effects of any caching. Unlikely as I drop and re-create the tables each time, but as I’ve already fallen foul of one assumption recently, I didn’t want to take any chances.
I’ve used tkprof to format tracefile information, so it’s probably worth bearing in mind the column heading definitions for tkprof output :
****************************************************************************** count = number of times OCI procedure was executed cpu = cpu time in seconds executing elapsed = elapsed time in seconds executing disk = number of physical reads of buffers from disk query = number of buffers gotten for consistent read current = number of buffers gotten in current mode (usually for update) rows = number of rows processed by the fetch or execute call ******************************************************************************
To generate the trace files, I’ve wrapped the anonymous blocks with the test code with the following statements.
Before the PL/SQL block containing the test code :
alter session set timed_statistics = true;
alter session set sql_trace = true;
alter session set tracefile_identifier = '<a string>';
…where <a string> is a string to include in the tracefile name to make it easier to find in the trace directory on the database server.
After the block :
alter session set sql_trace = false;
select value
from v$diag_info
where name = 'Default Trace File'
/
Let’s start by benchmarking just using SQL.
This is as fast as it gets in Oracle terms…generally speaking.
Therefore it should provide a useful indicator of what the RDBMS is capable of in terms of performing these DML operations ( straight_iud.sql ):
@setup.sql
set timing on
begin
insert into target_table(id)
select id from input_records;
update record_statuses
set status = 'LOADED'
where id in ( select id from input_records);
delete from input_records
where id in ( select id from record_statuses where status = 'LOADED');
commit;
end;
/
set timing off
Once the setup is done, the block completes in 1.878 seconds.
Whilst it may be faster than a fast thing on fast pills, a SQL-only solution is not always practical.
As Steven Feuerstein points out in his excellent article on this subject, there are times when you need PL/SQL to get the job done.
This is where the Bulk Collect/Forall and Cursor For Loop approaches come to the fore.
Let’s start by looking at how they compare when called upon to perform the first of our DML operations…
Let’s start with the straight SQL option (straight_insert.sql ):
@setup.sql
set timing on
begin
insert into target_table(id)
select id from input_records;
commit;
end;
/
set timing off
This runs in a predictably rapid 0.128 seconds.
Now for the Cursor For Loop ( forloop_insert.sql ):
@setup.sql
set timing on
declare
v_count pls_integer := 0;
begin
for r_rec in(
select id
from input_records)
loop
insert into target_table(id)
values( r_rec.id);
end loop;
commit;
end;
/
set timing off
…which completes in an, equally predictable, laggardly 1.445 seconds.
Incidentally, tracing this operation confirms that the select statement in a Cursor For Loop behaves in the same way as a Bulk Collect with the LIMIT set to 100. The Fetch count shows the 100K records have been fetched in batches of 100.
SELECT ID FROM INPUT_RECORDS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 2 0.00 0.00 0 0 0 0 Execute 2 0.00 0.00 0 0 0 0 Fetch 1002 0.43 0.38 154 328059 0 100000 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 1006 0.43 0.39 154 328059 0 100000
This brings us to the much vaunted Forall.
If we start by running with a limit of 100 on the Bulk Collect, we can get an idea of how much difference it makes when we minimize the context switches between the SQL and PL/SQL engine as compared to the humble Cursor For Loop ( forall_insert_100.sql ):
@../setup.sql
set timing on
declare
v_count pls_integer := 0;
cursor c_input is
select id
from input_records;
type typ_input is table of input_records%rowtype index by pls_integer;
v_arr_id typ_input;
begin
open c_input;
loop
fetch c_input
bulk collect into v_arr_id
limit 100;
forall i in 1..v_arr_id.count
insert into target_table(id)
values( v_arr_id(i).id);
exit when v_arr_id.count = 0;
end loop;
close c_input;
commit;
end;
/
set timing off
Yep, that’s much faster at 0.165 seconds.
We can conclude from this that most of the Cursor For Loop execution time is due to context switching between the SQL and PL/SQL engines.
However, after some trial and error, I’ve found that setting a limit of 1000 is about optimal for the test case at hand – not using a limit clause actually proves to be a bit slower – so I’ll be using that in the rest of the Bulk Collect tests in this post. Starting with this ( forall_insert.sql ):
@../setup.sql
set timing on
declare
v_count pls_integer := 0;
cursor c_input is
select id
from input_records;
type typ_input is table of input_records%rowtype index by pls_integer;
v_arr_id typ_input;
begin
open c_input;
loop
fetch c_input
bulk collect into v_arr_id
limit 1000;
forall i in 1..v_arr_id.count
insert into target_table(id)
values( v_arr_id(i).id);
exit when v_arr_id.count = 0;
end loop;
close c_input;
commit;
end;
/
set timing off
This runs in 0.145 seconds.
Let’s tabulate those execution times for ease of comparison :
RankMethodRuntime (seconds)1Simple SQL0.1282Forall (Limit 1000)0.1453Cursor For Loop1.445So far, it all seems to be pretty much as you might expect.
OK, let’s try some more DML statements…
We’re going to insert records into a table as before.
Then, using the same record set, we’ll update a second table then delete from a third table.
We’ve already seen the unadorned SQL script for this test, so let’s move on to the Cursor For Loop (forloop_iud.sql). Once I kick this off, you may want to take the opportunity to go and make a coffee…
@setup.sql
set timing on
declare
v_count pls_integer := 0;
begin
for r_rec in(
select id
from input_records)
loop
insert into target_table(id)
values( r_rec.id);
update record_statuses
set status = 'LOADED'
where id = r_rec.id;
delete from input_records
where id = r_rec.id;
end loop;
commit;
end;
/
set timing off
That took almost four minutes ( 238.486 seconds).
Let’s see what “much faster” looks like with Forall (forall_iud.sql ):
@setup.sql
set timing on
declare
v_count pls_integer := 0;
cursor c_input is
select id
from input_records;
type typ_input is table of input_records%rowtype index by pls_integer;
v_arr_id typ_input;
begin
open c_input;
loop
fetch c_input
bulk collect into v_arr_id
limit 1000;
forall i in 1..v_arr_id.count
insert into target_table(id)
values( v_arr_id(i).id);
forall j in 1..v_arr_id.count
update record_statuses
set status = 'LOADED'
where id = v_arr_id(j).id;
forall k in 1..v_arr_id.count
delete from input_records
where id = v_arr_id(k).id;
exit when v_arr_id.count = 0;
end loop;
close c_input;
commit;
end;
/
set timing off
My coffee’s gone cold. That’s 224.162 seconds – around 6% faster if you’re interested.
I’m not sure that qualifies as “much faster”.
Remember, the simple SQL runtime for the same DML operations was 1.878 seconds.
Time for another table :
RankMethodRuntime (seconds)1Simple SQL 1.8782Forall (Limit 1000)224.1623Cursor For Loop238.486In order to find out just what’s going on, it may be worth isolating a single DML operation, as we did with the INSERT statement earlier. This time, we’ll try an UPDATE…
Tracing an UpdateThe simple SQL benchmark for the update is ( straight_update.sql ):
@../setup.sql
insert into target_table
select id from input_records;
commit;
set timing on
begin
update record_statuses
set status = 'LOADED'
where id in ( select id from input_records);
commit;
end;
/
set timing off
This runs in 0.798 seconds.
Now for the Cursor For Loop ( forloop_update.sql):
@setup.sql
insert into target_table
select id from input_records;
commit;
set timing on
declare
v_count pls_integer := 0;
begin
for r_rec in(
select id
from input_records)
loop
update record_statuses
set status = 'LOADED'
where id = r_rec.id;
end loop;
commit;
end;
/
set timing off
144.856 seconds.
Now for the Forall (forall_update.sql ):
@setup.sql
insert into target_table(id)
select id from input_records;
commit;
set timing on
declare
v_count pls_integer := 0;
cursor c_input is
select id
from input_records;
type typ_input is table of input_records%rowtype index by pls_integer;
v_arr_id typ_input;
begin
open c_input;
loop
fetch c_input
bulk collect into v_arr_id
limit 1000;
forall j in 1..v_arr_id.count
update record_statuses
set status = 'LOADED'
where id = v_arr_id(j).id;
exit when v_arr_id.count = 0;
end loop;
close c_input;
commit;
end;
/
set timing off
That’s a not-much-faster-at-all-really 141.449 seconds.
RankMethodRuntime (seconds)1Simple SQL 0.7982Forall (Limit 1000)141.4493Cursor For Loop144.856Once I’ve turned tracing on and re-executed these scripts, the reason for the performance discrepancy becomes clear.
Here’s the tkprof output for the Simple SQL Update. Remember, query is the number of buffers gotten for a consistent read :
UPDATE RECORD_STATUSES SET STATUS = 'LOADED' WHERE ID IN ( SELECT ID FROM INPUT_RECORDS) call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 2 0 Execute 1 0.51 0.92 249 416 102416 100000 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.51 0.92 249 416 102418 100000
As you’d expect, the Cursor For Loop performs a huge number of gets by comparison as it’s executing 100K update statements, rather than just one :
UPDATE RECORD_STATUSES SET STATUS = 'LOADED' WHERE ID = :B1 call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 100000 215.15 221.86 248 25104059 103919 100000 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 100001 215.15 221.86 248 25104059 103919 100000
Now, although the Forall is only executing the insert 100 times, the number of gets is on a par with the Cursor For Loop :
UPDATE RECORD_STATUSES SET STATUS = 'LOADED' WHERE ID = :B1 call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 0 0 Execute 100 217.41 220.58 248 25105754 103319 100000 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 101 217.41 220.58 248 25105754 103319 100000
Further digging shows that it’s a similar story with the DELETEs.
At this point, maybe we should take another look at that documentation I quoted at the start. Specifically, the bit which says :
The FORALL statement runs one DML statement multiple times, with different values in the VALUES and WHERE clauses.
So, despite the tkprof execution count for the statement suggesting otherwise, it looks like Forall is actually running a seperate UPDATE statement for each value in the collection.
If we’re going to get this particular DML code to perform, we’ll need to look at storing our array in a structure other than a PL/SQL collection.
VARRAYIn their guise as a database object (as opposed to a PL/SQL collection), VARRAYs are directly visible to the SQL engine. This means that they can be directly referenced in SQL queries without the necessity for any context switching (varray_iud.sql) …
@setup.sql
-- If we try to declare and use the varray entirely within the PL/SQL block
-- we run into PLS-00642 : local collection types not allowed in SQL statements
-- so...
create or replace type prince_varray as varray(100000) of number
/
set timing on
declare
v_id_arr prince_varray := prince_varray();
begin
select id
bulk collect into v_id_arr
from input_records;
insert into target_table(id)
select * from table(v_id_arr);
update record_statuses
set status = 'LOADED'
where id in (select * from table(v_id_arr));
delete from input_records
where id in (select * from table(v_id_arr));
commit;
end;
/
set timing off
Side Note : some may consider it bad practice to name objects simply for the purposes of making a weak pun.
The big news is that the runtime is a rather respectable 1.846 seconds.
If you’re sure that you’re never going to need to process more than 32767 records in your VARRAY you can even save yourself the effort of coming up with a sensible name for one.
The following types are already created in Oracle for each of the base datatypes:
- sys.ODCINumberList
- sys.ODCIDateList
- sys.ODCIVarchar2List
Incidentally, in case you’re wondering about the maximum size of a VARRAY…
create or replace type varray_kane as varray(2147483647) of number / Type VARRAY_KANE compiled
Whilst a VARRAY is an option in this instance, in most cases, you’ll be dealing with a multi-dimensional array.
If only we could use a table…
Using a Global Temporary Table (GTT) offers all of the advantages of using a VARRAY with the added bonus that it’ll work for multi-dimensional arrays (gtt_iud.sql).
@setup.sql
drop table gtt_array;
create global temporary table gtt_array (
id number)
on commit delete rows;
set timing on
begin
insert into gtt_array
select id from input_records;
insert into target_table(id)
select id from gtt_array;
update record_statuses
set status = 'LOADED'
where id in (select id from gtt_array);
delete from input_records
where id in (select id from gtt_array);
commit;
end;
/
set timing off
Runtime is 1.950 seconds.
If we look at our final results table for the runs that involved all three DML statements, we can see that the performance of the VARRAY and GTT methods is broadly similar to that of using simple SQL statements, mainly because they are also, effectively simple SQL statements.
I say “broadly similar” because I’ve not found to one method to be consistently faster than the other two. All of them are, however, much faster than Forall.
RankMethodRuntime (seconds)1VARRAY 1.8462Simple SQL 1.8783GTT 1.9504Forall224.1625Cursor For Loop238.486 ConclusionsUsing Forall for an INSERT is likely to be significantly faster than using a Cursor For Loop due to the reduction in context switching. However, this does not hold for other types of DML.
If you find yourself in circumstances where performance is an issue then you may want to consider using a database object, such as a VARRAY or GTT, in your array processing.
Using a full outer join to “diff” two tables
I was inspired to write this post by Joshua Ottwell’s thoughts on finding rows present in one table but not another.
What follows is an exploration of how we can use a Full Outer Join to perform a “diff” on the data in two tables. We’ll also look at doing something similar for two distinct result sets from the same table.
In this instance, we want to identify :
- records that exist in the first table but not the second
- records that exist in the second table but not the first
- records that exist in both tables but where some values differ
Before going any further, I should say that the example that follows will make more sense if you consider Terry Pratchett’s observation that :
“In ancient times cats were worshipped as gods; they have not forgotten this.”
 You’ll need an offering if you want to use this computer !
The Family Firm
You’ll need an offering if you want to use this computer !
The Family Firm
Let’s say I have a report that I want to change.
I’ve simulated the output of the report and captured it in a table like this :
create table employee_report_baseline(
id number,
emp_name varchar2(100),
job_title varchar2(100) )
/
insert into employee_report_baseline( id, emp_name, job_title)
values(1,'DEBBIE', 'CEO');
insert into employee_report_baseline( id, emp_name, job_title)
values(2, 'MIKE', 'MINION');
insert into employee_report_baseline( id, emp_name, job_title)
values(3, 'TEDDY', 'DOG');
commit;
The output of the new version of the report is simulated like this :
create table employee_report_new
as
select *
from employee_report_baseline
where emp_name != 'MIKE';
update employee_report_new
set job_title = 'LADY-IN-WAITING'
where emp_name = 'DEBBIE';
insert into employee_report_new( id, emp_name, job_title)
values(4, 'CLEO', 'CAT');
commit;
First of all, let’s see if the records returned are the same for both reports. Happily ID is a unique key for the dataset, which makes the comparison fairly simple :
select bsl.id, nr.id,
case
when bsl.id is null then 'Added in New Report'
when nr.id is null then 'Missing from New Report'
end as status
from employee_report_baseline bsl
full outer join employee_report_new nr
on bsl.id = nr.id
where bsl.id is null
or nr.id is null
order by 1 nulls last;
The absence of the key value from either table indicates that the record is in one table but not the other.
Sure enough, when we run this query we get :
BASELINE_ID NEW_ID STATUS
----------- ------ ------------------------------
2 Missing from New Report
4 Added in New Report
All Differences
If we want to identify all of the differences, including changed records, we can do so with just a little extra typing :
select
nvl(bsl.id, nr.id) as id,
bsl.emp_name as old_emp_name,
nr.emp_name as new_emp_name,
bsl.job_title as old_job_title,
nr.job_title as new_job_title,
case
when bsl.id is null then 'Added in New Report'
when nr.id is null then 'Missing from New Report'
else 'Different between Report Versions'
end as status
from employee_report_baseline bsl
full outer join employee_report_new nr
on bsl.id = nr.id
where bsl.id is null
or nr.id is null
or nvl(bsl.emp_name, 'X') != nvl(nr.emp_name, 'X')
or nvl(bsl.job_title, 'X') != nvl(nr.job_title, 'X')
order by 1 nulls last
/
As well as the two records that are missing from either result set, we can see that Debbie has been demoted ( or possibly usurped). Cleo is now the top dog(!) :
 Comparing table definitions
Comparing table definitions
One thing to bear in mind when using a full outer join is that it will match any row in the tables being joined.
This gets a bit annoying when you want to do something with a subset of data such as comparing the column definitions of two tables in USER_TAB_COLUMNS in Oracle.
To demonstrate :
create table old_firm(
id number,
first_name varchar2(500),
last_name varchar2(500),
job_title varchar2(100),
start_date date,
end_date date)
/
create table new_firm(
id number,
first_name varchar2(250),
last_name varchar2(500),
salary number,
start_date date,
end_date varchar2(20))
/
If we want to compare only the records relating to these two tables then we’ll need a couple of in-line-views to restrict the result sets that our full outer join will look at.
Incidentally, as we’re running this on Oracle 19c, we can throw in an in-line function as well to save a bit of typing…
with function col_diff(
i_old_name in varchar2 default null,
i_new_name in varchar2 default null,
i_old_type in varchar2 default null,
i_new_type in varchar2 default null,
i_old_len in number default null,
i_new_len in number default null)
return varchar2
is
begin
if i_old_name is null then
return 'NEW';
elsif i_new_name is null then
return 'MISSING';
end if;
-- compare the attributes for the columns
if i_old_type != i_new_type then
return 'TYPE';
elsif i_old_len != i_new_len then
return 'LENGTH';
end if;
end;
ofm as (
select column_name, data_type, data_length
from user_tab_columns
where table_name = 'OLD_FIRM'),
nfm as (
select column_name, data_type, data_length
from user_tab_columns
where table_name = 'NEW_FIRM')
select
nvl(ofm.column_name, nfm.column_name) as column_name,
case col_diff( ofm.column_name, nfm.column_name, ofm.data_type, nfm.data_type, ofm.data_length, nfm.data_length)
when 'NEW' then 'New Column'
when 'MISSING' then 'Missing Column in NEW_FIRM'
when 'TYPE' then 'Type Mismatch. OLD_FIRM type is '||ofm.data_type||' NEW_FIRM is '||nfm.data_type
when 'LENGTH' then 'Length Mismatch. OLD_FIRM length is '||ofm.data_length||' NEW_FIRM is '||nfm.data_length
end as status
from ofm
full outer join nfm
on ofm.column_name = nfm.column_name
where (ofm.column_name is null or nfm.column_name is null)
or( ofm.data_type != nfm.data_type or ofm.data_length != nfm.data_length)
/

I’ll have to leave it there. The “boss” is demanding Dreamies to appease her wrath for being referred to as “top dog” earlier.
The Oracle SQL Limit Clause and teaching a New Dog Old Tricks
It’s been a few weeks now and I’ve finally gotten over England’s latest World Cup penalty drama.
I’m not so sure about Teddy though…
 “Merde !”
“Merde !”
Anyhow, he has decided that I need to know about the SQL Limit Clause that Oracle introduced in 12c and has decided to use data from the Tournament in the examples that follow…
EnvironmentThese examples have all been run on my OCI Free Tier database ( Oracle 19c at the time of writing).
The table we’re going to use contains details of players who scored or gave an assist during the recent Men’s World Cup Finals and looks like this :
create table goal_scorers (
player varchar2(4000),
team varchar2(500),
goals number,
assists number)
/
The table contains 176 rows.
select player, team, goals, assists from goal_scorers order by goals desc, assists desc / PLAYER TEAM GOALS ASSISTS ----------------------- ----------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 MORATA SPAIN 3 1 GONCALO RAMOS PORTUGAL 3 1 SAKA ENGLAND 3 0 RASHFORD ENGLAND 3 0 GAKPO NETHERLANDS 3 0 RICHARLISON BRAZIL 3 0 E VALENCIA ECUADOR 3 0 ... snip ... PRECIADO ECUADOR 0 1 MCGREE AUSTRALIA 0 1 RODRYGO BRAZIL 0 1
Before we get into the new(ish) syntax, let’s have a quick history lesson…
Before 12cBack in the mists of time, if you wanted to retrieve the first five rows in a table based on an order you specified, you’d need to do something like this :
select player, team, goals, assists
from (
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc, player, team)
where rownum <= 5;
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 GONCALO RAMOS PORTUGAL 3 1 5 rows selected.
Teddy reckons that you’ll only come across code like this if it’s really old…or written by a really old programmer.
Ignoring the cheeky young pup, we move on to the point were Analytic Functions become available (8i if you’re counting), which allows us to dispense with the – in this context – artificial order criteria of player and team and ensure that our query returns any tied records :
with top_scorers as (
select player, team, goals, assists,
rank() over ( order by goals desc, assists desc) as recnum
from goal_scorers )
select *
from top_scorers
where recnum <= 5
order by recnum;
PLAYER TEAM GOALS ASSISTS RECNUM -------------------- -------------------- ----- ------- ---------- MBAPPE FRANCE 8 2 1 MESSI ARGENTINA 7 3 2 ALVAREZ ARGENTINA 4 0 3 GIROUD FRANCE 4 0 3 MORATA SPAIN 3 1 5 GONCALO RAMOS PORTUGAL 3 1 5 6 rows selected.
In the latest Oracle versions, Teddy reckons that you can get that same analytical function goodness but with a bit less typing…
Fetch FirstLet’s re-write our top 5 query using the limit clause…
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
fetch first 5 rows only
/
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 MORATA SPAIN 3 1 5 rows selected.
As we’ve already seen, that’s ever so slightly different from the top 5 goal scorers. Like Morata, Goncalo Ramos also has 3 goals and 1 assist but he has been arbitrarily excluded from the result set.
Remember, Oracle does not guarantee the order of a result set of a SELECT statement other than that specified in the ORDER BY clause. Therefore, there’s no guarantee a future run of this query won’t include Goncalo Ramos and exclude Morata.
A more reliable query would include all of the tied records for 5th place, as with the RANK() query above.
Happily, we can achieve the same effect with a limit clause :
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
fetch first 5 rows with ties
/
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 MORATA SPAIN 3 1 GONCALO RAMOS PORTUGAL 3 1 6 rows selected.
As well as specifying a set number of rows, you can also specify a percentage using either the ONLY clause…
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
fetch first 5 percent rows only
/
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 MORATA SPAIN 3 1 GONCALO RAMOS PORTUGAL 3 1 SAKA ENGLAND 3 0 RASHFORD ENGLAND 3 0 GAKPO NETHERLANDS 3 0 9 rows selected.
… or the WITH TIES clause…
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
fetch first 5 percent rows with ties
/
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 MORATA SPAIN 3 1 GONCALO RAMOS PORTUGAL 3 1 SAKA ENGLAND 3 0 RASHFORD ENGLAND 3 0 GAKPO NETHERLANDS 3 0 RICHARLISON BRAZIL 3 0 E VALENCIA ECUADOR 3 0 11 rows selected.Offset
If we want to skip the first n rows we can use the OFFSET clause :
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
offset 10 rows
/
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- E VALENCIA ECUADOR 3 0 KANE ENGLAND 2 3 BRUNO FERNANDES PORTUGAL 2 1 LEWANDOWSKI POLAND 2 1 NEYMAR BRAZIL 2 1 ...snip... RODRYGO BRAZIL 0 1 166 rows selected.
We can also specify the number of rows to fetch in the offset clause :
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
offset 10 rows fetch next 10 rows only
/
or…
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
offset 10 rows fetch next 10 rows with ties
/
If you’re thinking of “paging” your results using this method, but you are not certain that your order by clause will not result in any ties, you may get some unexpected results.
For example, when I ran :
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
fetch first 10 rows only
/
I got :
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 MORATA SPAIN 3 1 GONCALO RAMOS PORTUGAL 3 1 E VALENCIA ECUADOR 3 0 SAKA ENGLAND 3 0 RICHARLISON BRAZIL 3 0 GAKPO NETHERLANDS 3 0 10 rows selected.
However, when I then ran…
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc
offset 10 rows fetch next 10 rows only
/
Gapko appeared again…
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- GAKPO NETHERLANDS 3 0 KANE ENGLAND 2 3 NEYMAR BRAZIL 2 1 LEWANDOWSKI POLAND 2 1 BRUNO FERNANDES PORTUGAL 2 1 TAREMI IRAN 2 1 ABOUBAKAR CAMEROON 2 1 CHO SOUTH KOREA 2 0 KRAMARIC CROATIA 2 0 AL DAWSARI SAUDI ARABIA 2 0 10 rows selected.
In this example, if I want to eliminate duplicates then I need to make sure that my order by clause does not allow any ties :
select player, team, goals, assists
from goal_scorers
order by goals desc, assists desc, player, team
fetch first 10 rows only
/
PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- MBAPPE FRANCE 8 2 MESSI ARGENTINA 7 3 ALVAREZ ARGENTINA 4 0 GIROUD FRANCE 4 0 GONCALO RAMOS PORTUGAL 3 1 MORATA SPAIN 3 1 E VALENCIA ECUADOR 3 0 GAKPO NETHERLANDS 3 0 RASHFORD ENGLAND 3 0 RICHARLISON BRAZIL 3 0 10 rows selected.
select player, team, goals, assists from goal_scorers order by goals desc, assists desc, player, team offset 10 rows fetch next 10 rows only / PLAYER TEAM GOALS ASSISTS -------------------- -------------------- ----- ------- SAKA ENGLAND 3 0 KANE ENGLAND 2 3 ABOUBAKAR CAMEROON 2 1 BRUNO FERNANDES PORTUGAL 2 1 LEWANDOWSKI POLAND 2 1 NEYMAR BRAZIL 2 1 TAREMI IRAN 2 1 AL DAWSARI SAUDI ARABIA 2 0 CHO SOUTH KOREA 2 0 DE ARRASCAETA URUGUAY 2 0 10 rows selected.
So that’s it then, give the dog a biscuit and be on our way ?
Well, it’s just possible that the rownum method from olden times is not ready to be consigned to history quite yet…
Let’s say we have a table with lots of rows…
create table bigtab as
select rownum as id from dual connect by rownum <= 10000000;
If we run the following queries against it, the relative performance may be a bit of a surprise…
set timing on
with ordered_recs as (
select id
from bigtab
order by 1)
select id
from bigtab
where rownum <=5;
ID
----------
1
2
3
4
5
Elapsed: 00:00:00.042
select id
from bigtab
order by id
fetch first 5 rows only;
ID
----------
1
2
3
4
5
Elapsed: 00:00:00.608
select id
from (
select id, rank() over (order by id) as recnum
from bigtab)
where recnum <= 5;
ID
----------
1
2
3
4
5
Elapsed: 00:00:00.636
Note that this is the second run of each query to account for the effects of caching.
The similarity in runtime between the limit clause and the analytic function is not that surprising. If you look at an explain plan for a limit clause query, it appears to be using analytical functions under the covers.
The big news here is that the shonky old rownum query is about 14 times faster than the shiny new limit clause equivalent.
Remember, I’m running this on an OCI 19c instance managed by Oracle so there’s nothing odd in the database configuration.
It appears that there is a patch to address an optimizer issue with this type of query, details of which can be found in this article by Nigel Bayliss.
However, if you do come across a performance issue with a limit clause query, it may be worth seeing if good old-fashioned rownum will dig you out of a hole.
Conditionally calling a script in a SQL*Plus control script
For those of us who haven’t quite gotten around to incorporating Liquibase in our database code release pipeline, we sometimes find ourselves in a situation where it would be extremely useful to be able to apply some branching logic in a SQL*Plus control script.
In order to save myself the pain of trying to figure out exactly how you can do this without writing lots of dynamic code, I’ve decided to write it down.
NOTE – the scripting techniques outlined here work the same way in both SQLCL and SQL*Plus.
What follows are examples of SQL*Plus scripts which implement branching to :
- choose which of two scripts to run
- choose whether or not to run a script
The difference between these two use cases is fairly subtle, but worth exploring…
Choosing between two scriptsHere are two very simple scripts. The first is called weekday.sql :
prompt Another working day :-(…and the second is called weekend.sql
prompt Yay, it's the weekend :-)I want to write a control script which calls one – and only one – of these scripts based on what day it is today.
We can establish the day easily enough with :
select to_char(sysdate, 'DY') from dual;In order to use this information to influence the behaviour of the control script at runtime, we’ll need to assign it to a variable that we can reference. In SQL*PLUS, we can do this with NEW_VALUE :
column weekday new_value v_script noprint
select
case when to_char(sysdate, 'DY') in ('SAT', 'SUN')
then 'weekend.sql'
else 'weekday.sql'
end as weekday
from dual;
@&v_script
The first line of the script…
column weekday new_value v_script noprint…takes the value of the column “weekday” from result of the subsequent query and assigns it to the variable v_script.
I’ve saved this script as choose_message.sql.
When I run it I get :

As you can see, only the message from weekend.sql is shown. The weekday.sql script is not executed.
Choosing whether or not to run a scriptThis is a little different as, with this technique, the script will always call a file at the end.
Therefore, I’ve got a placeholder script which will get executed if we decide we don’t want to run the actaul target script. The new script is placeholder.sql and is predictably simple :
prompt You have chosen to skip weekday.sqlThis time, the control script is called run_weekday_yn.sql and accepts a parameter :
set verify off
accept run_yn prompt 'Do you want to run the script ? (Y/N) : '
column run_it new_value v_script noprint
select
case when upper('&run_yn') = 'Y'
then 'weekday.sql'
else 'placeholder.sql'
end run_it
from dual;
@&v_script
This will run weekday.sql…
…but only if we tell it to…

Of course, you can use a positional notation for the parameter to allow it to be passed unprompted at runtime. This is run_it_yn.sql :
set verify off
column run_it new_value v_script noprint
select
case
when upper('&1') = 'Y' then 'weekday.sql'
else 'placeholder.sql'
end run_it
from dual;
@&v_script
